CTable and .b2z: Querying Tabular Data, the Blosc Way
Here is a question we have been chasing, in one form or another, for more than fifteen years: how much work can you avoid doing if your data is stored the right way?
In this post we put that question to a concrete test: one selective query against 24.3 million Chicago taxi trips, stored on disk in two formats — Parquet and the new persistent .b2z format for TreeStore and other Blosc2 objects — and answered by five different tools: DuckDB, PyArrow, pandas, polars, and Blosc2's own CTable. But let me first tell you how we got here, because CTable did not appear out of thin air: it is the fourth floor of a building whose foundations were laid in 2009.
From a turbo-charged compressor...
Blosc (acronym for BLOcked, Shuffled and Compressed) was born with a single, then-heretical idea: that compression could make data access faster, not slower. CPUs were (and are) starving — they can crunch numbers far faster than memory can feed them — so if you split data into blocks that fit in CPU caches, shuffle the bytes so that similar ones sit together, and decompress with all your cores, the time spent decompressing can be smaller than the time saved moving fewer bytes. "Compress faster than memcpy" was the provocative benchmark slogan of the time.
That first Blosc was humble: a blocked, multithreaded meta-compressor for binary buffers. No containers, no files, no types. Just speed.
...to containers, arrays, and a compute engine
The next decade taught us that a fast compressor alone is not enough; data needs a home. C-Blosc2 (2.0 released in 2021) gave it one: 64-bit super-chunks, persistent frames, a richer filter pipeline, modern codecs, and a plugin system. On the Python side, this matured into Python-Blosc2.
2023 came with both NDim and NDArray: a compressed, n-dimensional array, with a two-level partitioning scheme — chunks, sized to fit comfortably in higher-level CPU caches, divided into blocks — where the block is the unit of decompression, sized to fit comfortably in lower-level CPU caches. Slicing an NDArray decompresses only the blocks that the slice touches, and several blocks can be decompressed in parallel too (as long as they belong to the same chunk). Keep that sentence in mind; it is important for what comes below.
On top of that, Python-Blosc2 3.0 (early 2025) added a compute engine: lazy expressions like a + b * 2 that evaluate block by block, straight over compressed (possibly larger-than-RAM) operands, and return NumPy arrays. The engine never materializes whole arrays; it streams cache-sized blocks through the CPU. At this point we had fast compressed storage and fast compute over it — what we were missing was a way to talk about tables.
CTable: a columnar table on Blosc2 foundations
CTable (introduced in 2026) is exactly that: a columnar table where each column is an NDArray (or a ListArray for variable-length data), with typed schemas, nullable columns, and a where() method (among others) that accepts plain Python expressions and is executed by the compute engine.
Because columns are NDArrays, every column inherits the block structure — and this is where the design clicks together. CTable can build indexes for each column (like min/max statistics kept at block granularity). When a query like t.payment.tips > 100 arrives, blocks whose maximum tip is below 100 are never read and never decompressed. The index granularity is exactly aligned with the unit of work it avoids.
A CTable persists inside a .b2z file: the single-file, zip-based flavor of a persistent TreeStore that holds all columns, indexes and metadata in one compact, openable-anywhere container. Like Parquet, the data stays compressed on disk; unlike Parquet, you can open it and immediately get NumPy-addressable columns, no engine in between.
Now, where does the fourth floor hold the weight? Time to experiment.
The benchmark setup: one selective query, five tools
The dataset is the classic Chicago Taxi trips table, with a selection of 24.3 million rows, 14 columns (floats, timestamps, dictionary-encoded strings, and even a variable-length GPS path per trip). The query is a typical needle-in-a-haystack filter with projection and sort:
columns = ["payment.tips", "payment.total", "trip.sec", "trip.km", "company"] condition = (t.payment.tips > 100) & (t.trip.km > 0) & (t.trip.begin.lon < 0) result = t.where(condition, columns=columns).sort_by("trip.sec")
or, in SQL:
SELECT payment.tips, payment.total, trip.sec, trip.km, company WHERE payment.tips > 100 AND trip.km > 0 AND trip.begin.lon < 0 ORDER BY trip.sec
Only 67 of 24.3 million rows match — a highly selective query, which is precisely the regime where indexing can shine.
The contenders: DuckDB, PyArrow, pandas and polars querying the Parquet file, and Blosc2's CTable querying the .b2z. Every tool reads from disk on demand; nothing is preloaded. Each engine runs in a fresh subprocess, and it reports the query time each script measures internally, excluding interpreter and import overhead. Cold-cache runs happen right after flushing the OS file cache (sudo purge); warm runs are best-of-7. The machine is a Mac mini (Apple M4 Pro) with 24 GB RAM. The full, reproducible notebook is in the python-blosc2 repository.
First, the storage footprint:
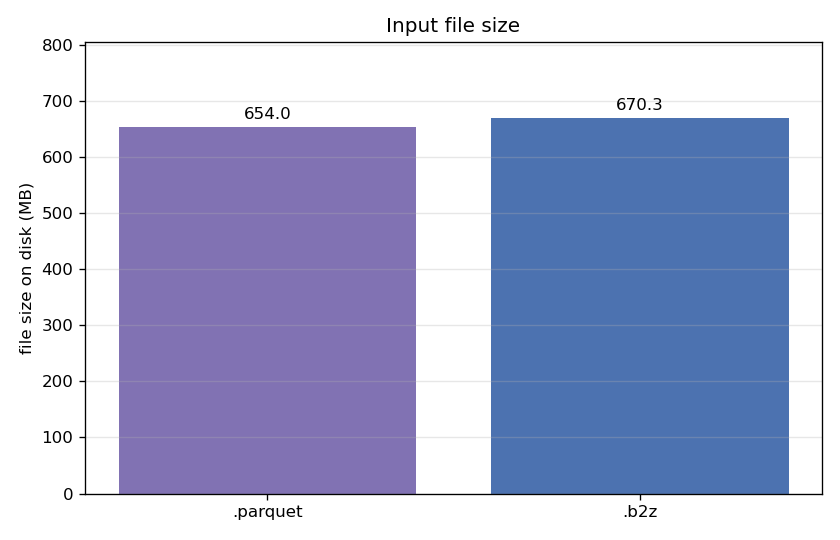
The .b2z lands at 670 MB versus Parquet's 654 MB — a 2% premium. Those extra bytes are mostly the block-level indexes. It is important to note that these indexes are computed automatically when importing a Parquet file into a CTable .b2z file.
Cold cache: reading less wins
The cold run is the scenario we care most about: you have a large file on disk, it is not in the OS cache, and you want one answer, fast.
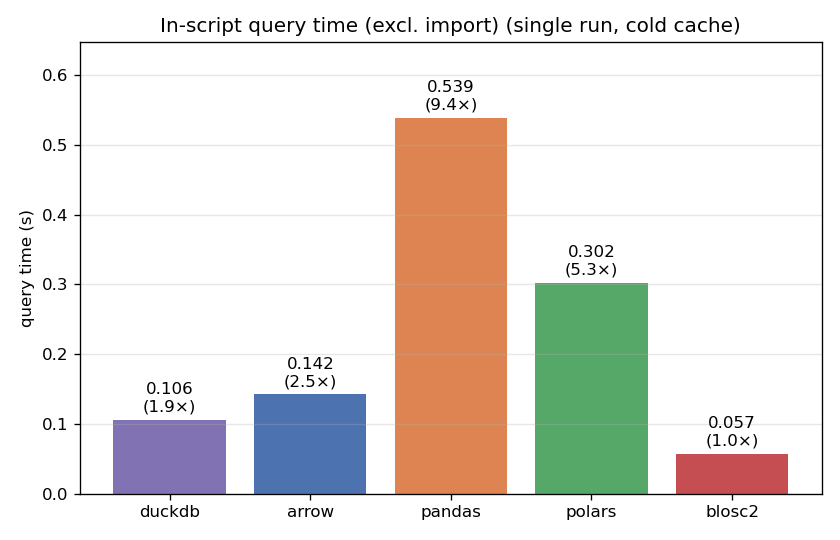
CTable answers in 0.057 s — about 1.9x faster than DuckDB (0.106 s), 2.5x faster than PyArrow, 5.3x faster than polars and 9.4x faster than pandas. It is important to note that all methods try to use streaming and filter pushdown where possible, although pandas is not designed for that, and it shows; interestingly polars is more advanced in that regard.
The reason why CTable can go faster is fine-grained indexing (min/max on blocks). On a cold cache, the dominant cost is bytes coming off the disk. The indexes let CTable prune roughly 90% of the blocks for this query: those blocks are neither read nor decompressed. Pruning pays twice — less I/O and less CPU — and on a first-touch query the I/O half is the whole ballgame. Parquet also has min/max statistics, but at a coarser row-group granularity, which for this query can prune nothing (see below).
Warm cache: a dead heat with a real database
Once the file is fully cached in RAM, I/O is nearly free and raw engine throughput takes over. This is DuckDB's home turf — a vectorized, multithreaded analytical SQL engine with filter pushdown and late materialization.
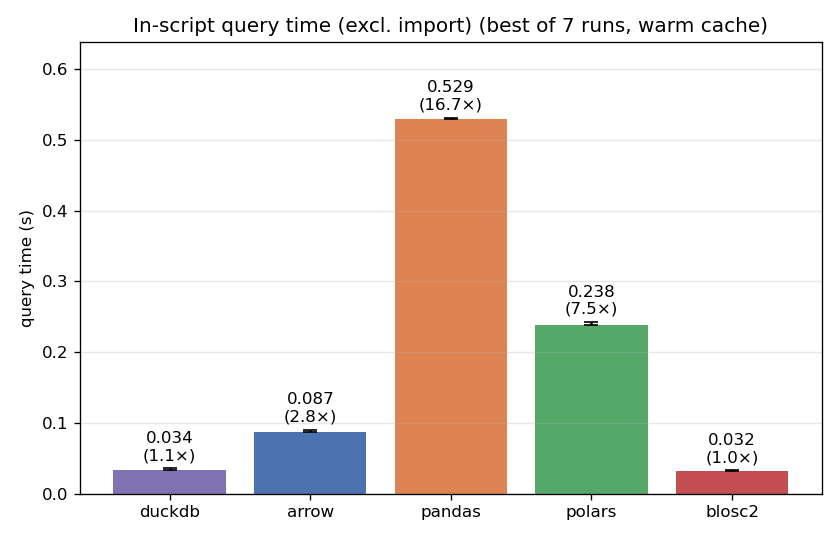
CTable finishes in 0.032 s, DuckDB in 0.034 s — a dead heat (the two trade places within run-to-run noise), with both about 2.8x ahead of PyArrow, ~7x ahead of polars, and ~16x ahead of pandas. We find this result remarkable because Blosc2 brings no SQL engine: a storage container + compute + indexing engine holding the tie with a purpose-built database tells us the layout is doing the heavy lifting. Again, this layout is determined automatically, so users get the benefit without tuning.
Memory tells a similar story:
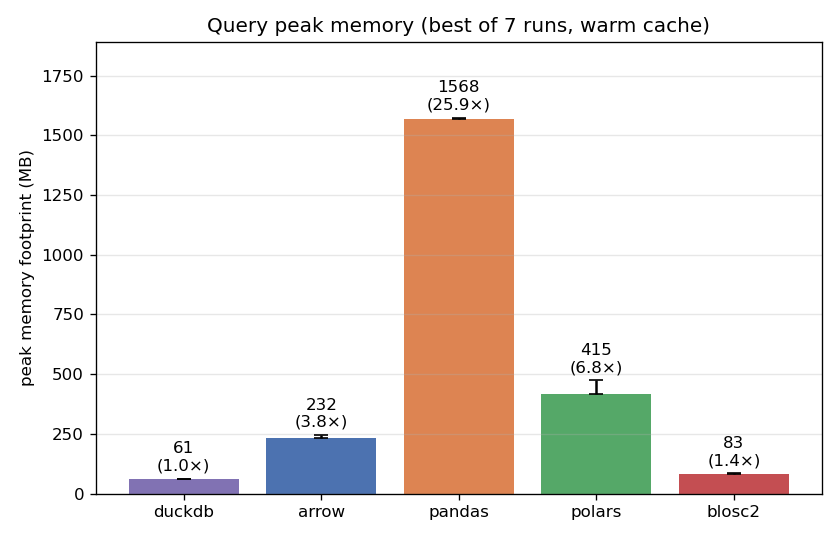
DuckDB (~61 MB) and CTable (~83 MB) are the two leanest by a wide margin — more than an order of magnitude below pandas (~1.6 GB), which materializes full columns before filtering. polars can make use of better streaming, while PyArrow is still better, but both are still much heavier than the two leaders. This is important for large datasets that may not fit comfortably in RAM, because that means that larger-than-RAM queries are more likely to succeed without hitting swap when using CTable or DuckDB.
Why pruning wins: granularity
Parquet also carries min/max statistics — at row-group granularity, here ~970,000 rows per group. CTable keeps them at block granularity, ~27,000 rows per block: roughly 36x finer. A Blosc2 block is the unit of decompression — the same cache-sized block the compute engine streams. An index at a coarser granularity than the I/O unit can only skip work in big, lucky lumps. Choosing an appropriate block size is important, and this is automatically handled by Blosc2 when importing from Parquet.
Note that the advantage of indexes rides on selectivity, not on any general superiority. tips > 100 is rare enough that most 27K-row blocks contain no match.
Conclusions
Several interesting takeaways emerge from this experiment:
For selective cold queries on large tabular files, CTable/.b2z is genuinely fast — the fastest of the five tools here, on a query and dataset it was not specially tuned for. If your workload looks like "open a big file, fetch a small subset, move on", the block-level indexing earns its 2% of disk many times over.
Warm, it ties. DuckDB remains an excellent engine, and on cached data it matches CTable while speaking full SQL with joins and aggregations that CTable cannot cover (at least not yet). If your problems are relational, use a relational engine.
The result is arrays, not a result set.
t.where(...)hands back NumPy-addressable columns with their original dtypes — no.to_numpy()hop, no DataFrame conversion tax. For NumPy-centric pipelines, that removes a whole impedance layer. And since columns are NDArrays, a CTable column can even be n-dimensional, or hold variable-length data (this dataset stores a GPS trace per row).Parquet is not going anywhere. It remains the lingua franca of the data ecosystem, readable by everything.
.b2zis young and its natural habitat is the Python/NumPy world. What this experiment shows is that the trade is real and the price is modest: a couple percent of disk for first-touch queries that run in a fraction of the time.
Sixteen years after asking whether compression could be faster than memcpy, the question has scaled up but taken on a slightly different shape: the fastest byte is the one you never touch. Blocks sized for caches made decompression cheap; the compute engine made math over blocks cheap; and CTable's block-level indexes now make not touching most of a table cheap, too. The fourth floor stands on the three below it.
Reproduce it yourself
Everything in this post lives in bench/chicago-taxi. The notebook, the driver, the five per-engine query scripts, and a README with the details. The notebook downloads the dataset on first run and builds the .b2z from it, so the whole thing is two commands away:
More info
Introducing CTable — the design and feature tour
The benchmark directory — notebook, driver, per-engine scripts and README
Acknowledgments
The benchmark uses the Taxi Trips dataset published by the City of Chicago under its open data program. Thanks also to the NumFOCUS foundation and our sponsors for making sustained work on Blosc possible.
Enjoy data!
Comments
Comments powered by Disqus