C-Blosc2 Enters Beta Stage
The first beta version of C-Blosc2 has been released today. C-Blosc2 is the new iteration of C-Blosc 1.x series, adding more features and better documentation and is the outcome of more than 4 years of slow, but steady development. This blog entry describes the main features that you may see in next generation of C-Blosc, as well as an overview of what is in our roadmap.
Note 1: C-Blosc2 is currently in beta stage, so not ready to be used in production yet. Having said this, being in beta means that the API has been declared frozen, so there is guarantee that your programs will continue to work with future versions of the library. If you want to collaborate in this development, you are welcome: have a look at our roadmap below and contribute PR's or just go to the open issues and help us with them.
Note 2: the term C-Blosc1 will be used instead of the official C-Blosc name for referring to the 1.x series of the library. This is to make the distinction between the C-Blosc 2.x series and C-Blosc 1.x series more explicit.
Main features in C-Blosc2
New 64-bit containers
The main container in C-Blosc2 is the super-chunk or, for brevity, schunk, that is made by smaller containers which are essentially C-Blosc1 32-bit containers. The super-chunk can be backed (or not) by another container which is called a frame. If a schunk is not backed by a frame (the default), the different chunks will be stored sparsely in-memory.
The frame object allows to store super-chunks contiguously, either on-disk or in-memory. When a super-chunk is backed by a frame, instead of storing all the chunks sparsely in-memory, they are serialized inside the frame container. The frame can be stored on-disk too, meaning that persistence of super-chunks is supported and that data can be accessed using the same API independently of where it is stored, memory or disk.
Finally, the user can add meta-data to frames for different uses and in different layers. For example, one may think on providing a meta-layer for NumPy so that most of the meta-data for it is stored in a meta-layer; then, one can place another meta-layer on top of the latter can add more high-level info (e.g. geo-spatial, meteorological...), if desired.
When taken together, these features represent a pretty powerful way to store and retrieve compressed data that goes well beyond of the previous contiguous compressed buffer, 32-bit limited, of C-Blosc1.
New filters and filters pipeline
Besides shuffle and bitshuffle already present in C-Blosc1, C-Blosc2 already implements:
delta: the stored blocks inside a chunk are diff'ed with respect to first block in the chunk. The basic idea here is that, in some situations, the diff will have more zeros than the original data, leading to better compression.
trunc_prec: it zeroes the least significant bits of the mantissa of float32 and float64 types. When combined with the shuffle or bitshuffle filter, this leads to more contiguous zeros, which are compressed better and faster.
Also, a new filter pipeline has been implemented. With it, the different filters can be pipelined so that the output of one filter can be the input for the next; this happens at the block level, so minimizing the size of temporary buffers, and hence, accelerating the process. Possible examples of pipelines are a delta filter followed by shuffle, or a trunc_prec followed by bitshuffle. Up to 6 filters can be pipelined, so there is plenty of space for upcoming new filters to collaborate among them.
More SIMD support for ARM and PowerPC
New SIMD support for ARM (NEON), allowing for faster operation on ARM architectures. Only shuffle is supported right now, but the idea is to implement bitshuffle for NEON too.
Also, SIMD support for PowerPC (ALTIVEC) is here, and both shuffle and bitshuffle are supported. However, this has been done via a transparent mapping from SSE2 into ALTIVEC emulation in GCC 8, so performance could be better (but still, it is already a nice improvement over native C code; see PR https://github.com/Blosc/c-blosc2/pull/59 for details). Thanks to Jerome Kieffer.
New codecs
There is a new Lizard codec, which is an efficient compressor with very fast decompression. It achieves compression ratio that is comparable to zip/zlib and zstd/brotli (at low and medium compression levels) that is able to attain decompression speeds of 1 GB/s or more.
New dictionary support for better compression ratio
Dictionaries allow for better discovery of data duplicates among different blocks: when a block is going to be compressed, C-Blosc2 can use a previously made dictionary (stored in the header of the super-chunk) for compressing all the blocks that are part of the chunks. This usually improves the compression ratio, as well as the decompression speed, at the expense of a (small) overhead in compression speed. Currently, this is only supported in the zstd codec, but would be nice to extend it to lz4 and blosclz at least.
Much improved documentation mark-up
We are currently using a combination of Sphinx + Doxygen + Breathe for documenting the C API for C-Blosc2. This is a huge step further compared with the documentation of C-Blosc1, where the developer needed to go the blosc.h header for reading the docstrings there. Thanks to Alberto Sabater for contributing the support for this.
Support for Intel IPP (Integrated Performance Primitives)
Intel is producing a series of optimizations in their IPP library and among them, and accelerated version of the LZ4 codec. Due to its excellent compression capabilities and speed, LZ4 is probably the most used codec in Blosc, so enabling even a bit more of optimization on LZ4 is always a good news. And judging by the plots below, the Intel guys seem to have done an excellent job:
|
|
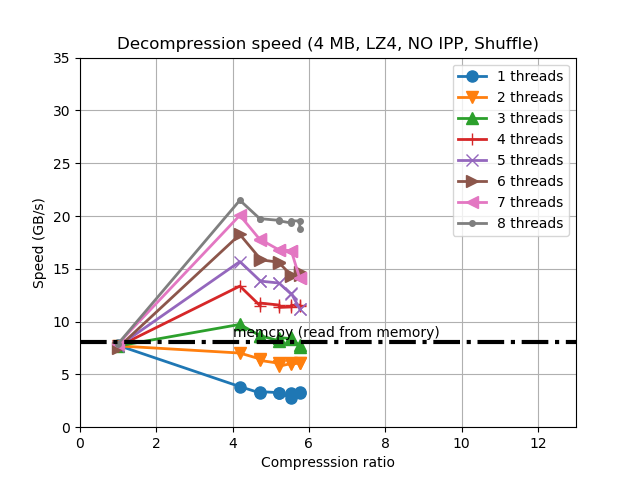
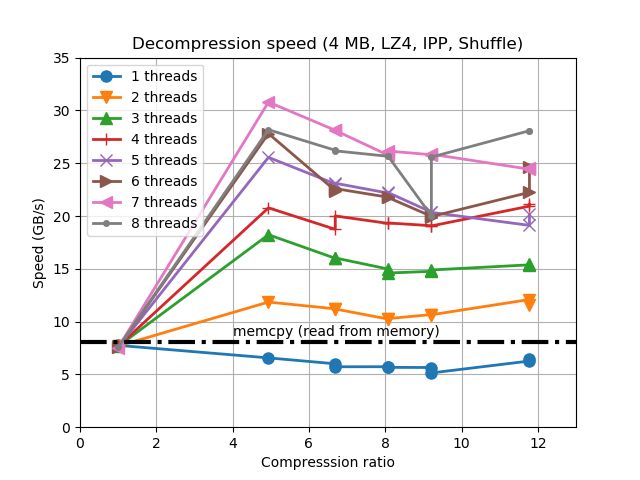
In the plots above we see a couple of things: 1) the IPP/LZ4 functions can compress more than regular LZ4, and 2) they are quite a bit faster than regular LZ4. As always, take these plots with a grain of salt, as actual datasets will see more similar compression ratios and speed (but still, the difference can be significant). Of course, IPP/LZ4 should generate LZ4 chunks that are completely compatible with the original LZ4 library (but in case you detect any incompatibility, please shout!).
C-Blosc2 beta.1 comes with support for LZ4/IPP out-of-the-box, that is, if IPP is detected in the system, its optimized LZ4 functions are automatically linked and used with the Blosc2 library. If, for portability or other reasons, you don't want to create a Blosc2 library that is linked with Intel IPP, you can disable support for it passing the -DDEACTIVATE_IPP=ON to cmake. In the future, we surely may give support for other optimized codecs in IPP too (Zstd would be an excellent candidate).
Roadmap
Of course, C-Blosc2 is not done yet, and there are many interesting enhancements that we would like to tackle sooner or later. Here it is a more or less comprehensive list of our roadmap:
Lock support for super-chunks: when different processes are accessing concurrently to super-chunks, make them to sync properly by using locks, either on-disk (frame-backed super-chunks), or in-memory.
Checksums: the frame can benefit from having a checksum per every chunk/index/metalayer. This will provide more safety towards frames that are damaged for whatever reason. Also, this would provide better feedback when trying to determine the parts of the frame that are corrupted. Candidates for checksums can be the xxhash32 or xxhash64, depending on the gaols (to be decided).
-
Documentation: utterly important for attracting new users and making the life easier for existing ones. Important points to have in mind here:
Quality of API docstrings: is the mission of the functions or data structures clearly and succinctly explained? Are all the parameters explained? Is the return value explained? What are the possible errors that can be returned?
Tutorials/book: besides the API docstrings, more documentation materials should be provided, like tutorials or a book about Blosc (or at least, the beginnings of it). Due to its adoption in GitHub and Jupyter notebooks, one of the most extended and useful markup systems is MarkDown, so this should also be the first candidate to use here.
Wrappers for other languages: Python and Java are the most obvious candidates, but others like R or Julia would be nice to have. Still not sure if these should be produced and maintained by the Blosc development team, or leave them for third-party players that would be interested.
It would be nice to use LGTM, a CI-friendly analyzer for security.
Add support for buildkite as another CI would be handy because it allows to use on-premise machines, potentially speeding-up the time to do the builds, but also to setup pipelines with more complex dependencies and analyzers.
The implementation of these features will require the help of people, either by contributing code (see our developing guidelines) or, as it turns out that Blosc is a project sponsored by NumFOCUS, you may want to make a donation to the project. If you plan to contribute in any way, thanks so much in the name of the community!
Addendum: Special thanks to developers
C-Blosc2 is the outcome of the work of many developers that worked not only on C-Blosc2 itself, but also on C-Blosc1, from which C-Blosc2 inherits a lot of features. I am very grateful to Jack Pappas, who contributed important portability enhancements, specially runtime and cross-platform detection of SSE2/AVX2 (with the help of Julian Taylor) as well as high precision timers (HPET) which are essential for benchmarking purposes. Lucian Marc also contributed the support for ARM/NEON for the shuffle filter. Jerome Kieffer contributed support for PowerPC/ALTIVEC. Alberto Sabater, for his great efforts on producing really nice Blosc2 docs, among other aspects. And last but not least, to Valentin Haenel for general support, bug fixes and other enhancements through the years.
** Enjoy Data!**
Comments
Comments powered by Disqus