Bytedelta: Enhance Your Compression Toolset
Bytedelta is a new filter that calculates the difference between bytes in a data stream. Combined with the shuffle filter, it can improve compression for some datasets. Bytedelta is based on initial work by Aras Pranckevičius.
TL;DR: We have a brief introduction to bytedelta in the 3rd section of this presentation.
The basic concept is simple: after applying the shuffle filter,
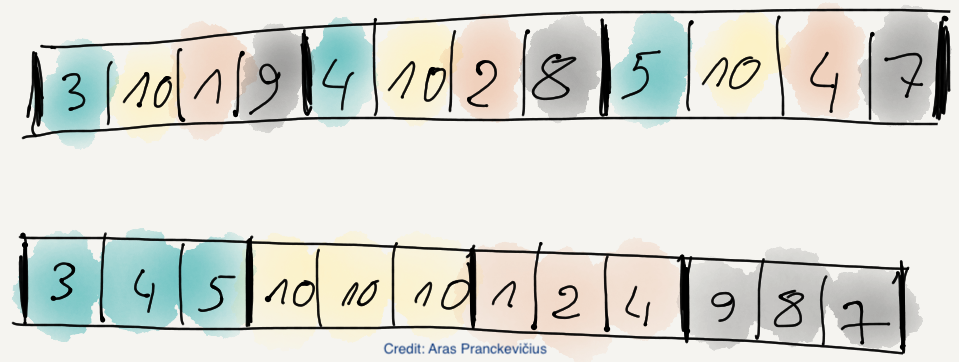
then compute the difference for each byte in the byte streams (also called splits in Blosc terminology):
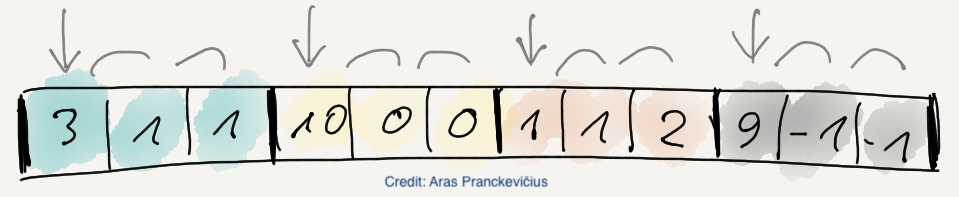
The key insight enabling the bytedelta algorithm lies in its implementation, especially the use of SIMD on Intel/AMD and ARM NEON CPUs, making the filter overhead minimal.
Although Aras's original code implemented shuffle and bytedelta together, it was limited to a specific item size (4 bytes). Making it more general would require significant effort. Instead, for Blosc2 we built on the existing shuffle filter and created a new one that just does bytedelta. When we insert both in the Blosc2 filter pipeline (it supports up to 6 chained filters), it leads to a completely general filter that works for any type size supported by existing shuffle filter.
With that said, the implementation of the bytedelta filter has been a breeze thanks to the plugin support in C-Blosc2. You can also implement your own filters and codecs on your own, or if you are too busy, we will be happy to assist you.
Compressing ERA5 datasets
The best approach to evaluate a new filter is to apply it to real data. For this, we will use some of the ERA5 datasets, representing different measurements and labeled as "wind", "snow", "flux", "pressure" and "precip". They all contain floating point data (float32) and we will use a full month of each one, accounting for 2.8 GB for each dataset.
The diverse datasets exhibit rather dissimilar complexity, which proves advantageous for testing diverse compression scenarios. For instance, the wind dataset appears as follows:
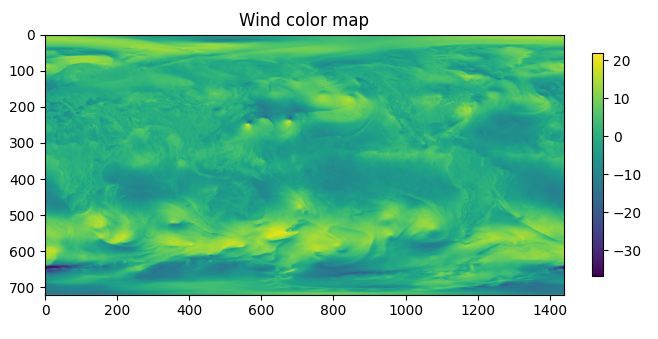
The image shows the intricate network of winds across the globe on October 1, 1987. The South American continent is visible on the right side of the map.
Another example is the snow dataset:
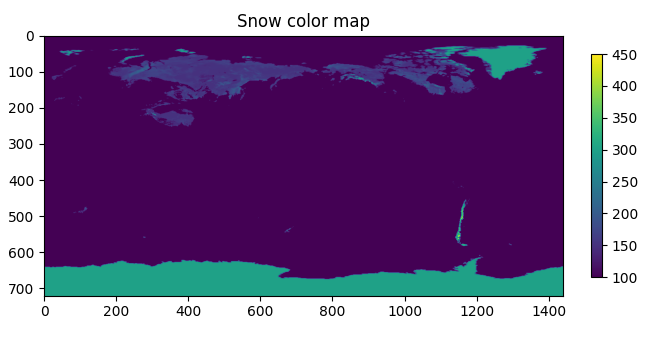
This time the image is quite flat. Here one can spot Antarctica, Greenland, North America and of course, Siberia, which was pretty full of snow by 1987-10-01 23:00:00 already.
Let's see how the new bytedelta filter performs when compressing these datasets. All the plots below have been made using a box with an Intel i13900k processor, 32 GB of RAM and using Clear Linux.
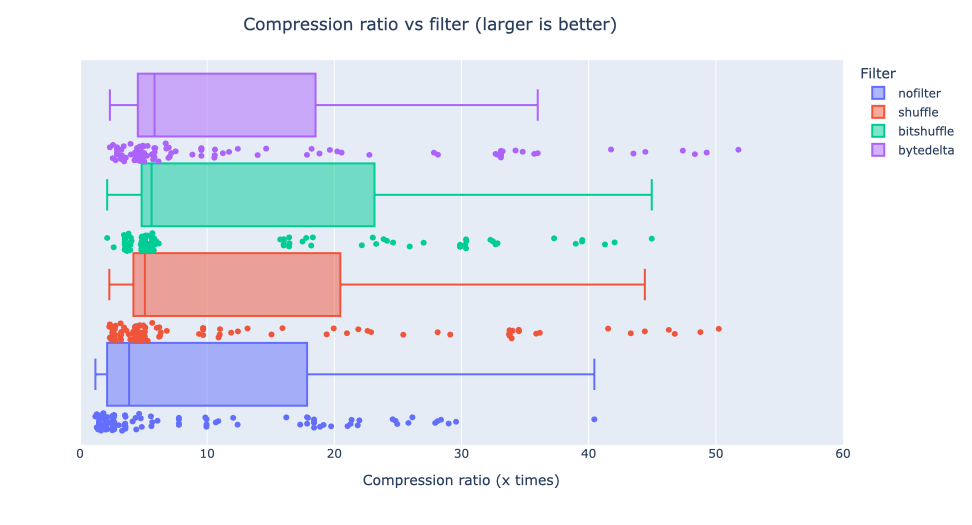
In the box plot above, we summarized the compression ratios for all datasets using different codecs (BLOSCLZ, LZ4, LZ4HC and ZSTD). The main takeaway is that using bytedelta yields the best median compression ratio: bytedelta achieves a median of 5.86x, compared to 5.62x for bitshuffle, 5.1x for shuffle, and 3.86x for codecs without filters. Overall, bytedelta seems to improve compression ratios here, which is good news.
While the compression ratio is a useful metric for evaluating the new bytedelta filter, there is more to consider. For instance, does the filter work better on some data sets than others? How does it impact the performance of different codecs? If you're interested in learning more, read on.
Effects on various datasets
Let's see how different filters behave on various datasets:
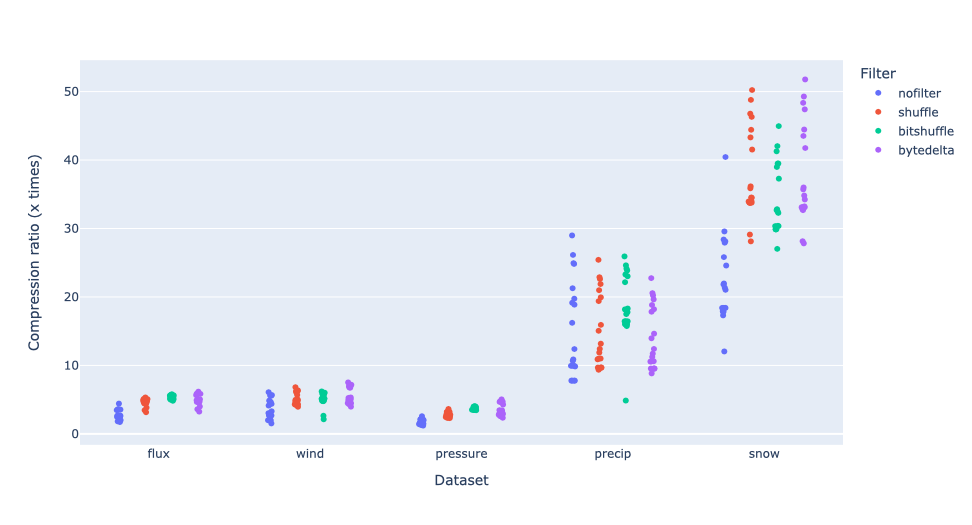
Here we see that, for datasets that compress easily (precip, snow), the behavior is quite different from those that are less compressible. For precip, bytedelta actually worsens results, whereas for snow, it slightly improves them. For less compressible datasets, the trend is more apparent, as can be seen in this zoomed in image:
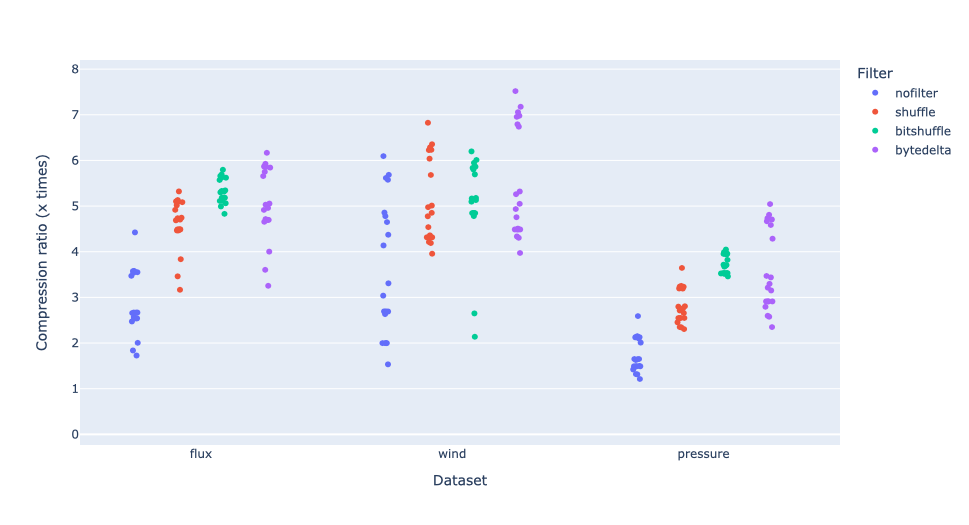
In these cases, bytedelta clearly provides a better compression ratio, most specifically with the pressure dataset, where compression ratio by using bytedelta has increased by 25% compared to the second best, bitshuffle (5.0x vs 4.0x, using ZSTD clevel 9). Overall, only one dataset (precip) shows an actual decrease. This is good news for bytedelta indeed.
Furthermore, Blosc2 supports another compression parameter for splitting the compressed streams into bytes with the same significance. Normally, this leads to better speed but less compression ratio, so this is automatically activated for faster codecs, whereas it is disabled for slower ones. However, it turns out that, when we activate splitting for all the codecs, we find a welcome surprise: bytedelta enables ZSTD to find significantly better compression paths, resulting in higher compression ratios.
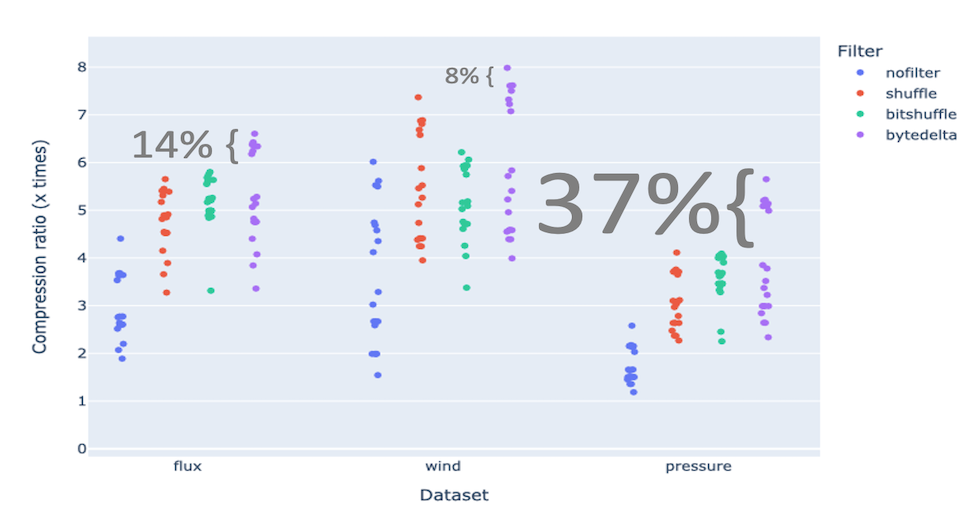
As can be seen, in general ZSTD + bytedelta can compress these datasets better. For the pressure dataset in particular, it goes up to 5.7x, 37% more than the second best, bitshuffle (5.7x vs 4.1x, using ZSTD clevel 9). Note also that this new highest is 14% more than without splitting (the default).
This shows that when compressing, you cannot just trust your intuition for setting compression parameters - there is no substitute for experimentation.
Effects on different codecs
Now, let's see how bytedelta affects performance for different codecs and compression levels.
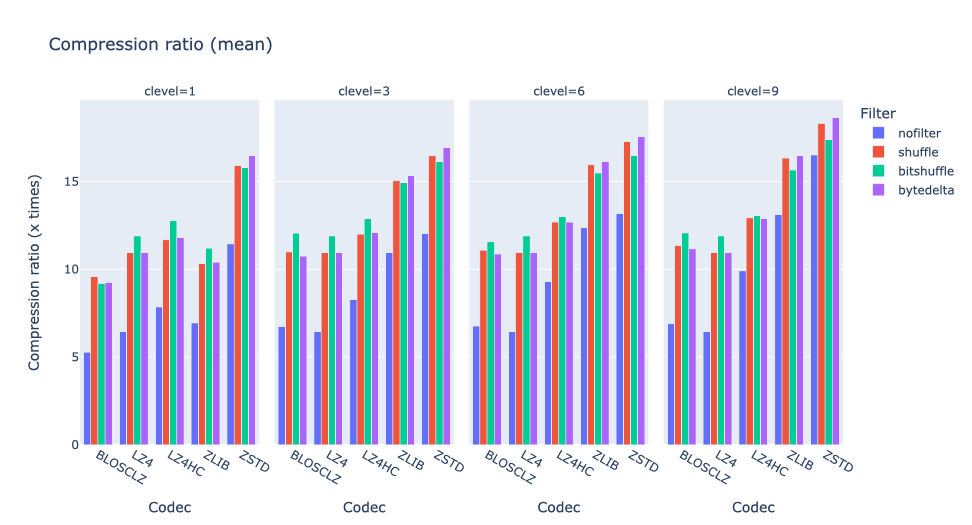
Interestingly, on average bytedelta proves most useful for ZSTD and higher compression levels of ZLIB (Blosc2 comes with ZLIB-NG). On the other hand, the fastest codecs (LZ4, BLOSCLZ) seem to benefit more from bitshuffle instead.
Regarding compression speed, in general we can see that bytedelta has little effect on performance:
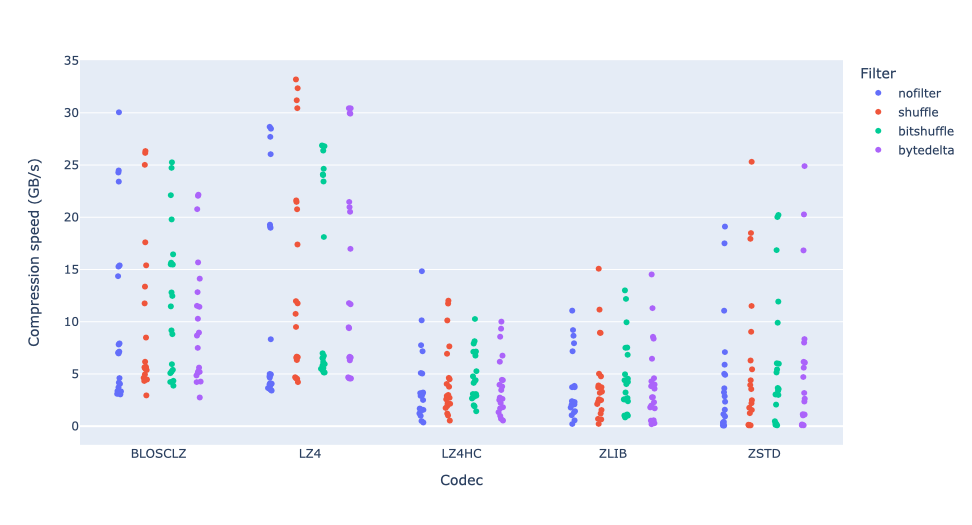
As we can see, compression algorithms like BLOSCLZ, LZ4 and ZSTD can achieve extremely high speeds. LZ4 reaches and surpasses speeds of 30 GB/s, even when using bytedelta. BLOSCLZ and ZSTD can also exceed 20 GB/s, which is quite impressive.
Let’s see the compression speed grouped by compression levels:
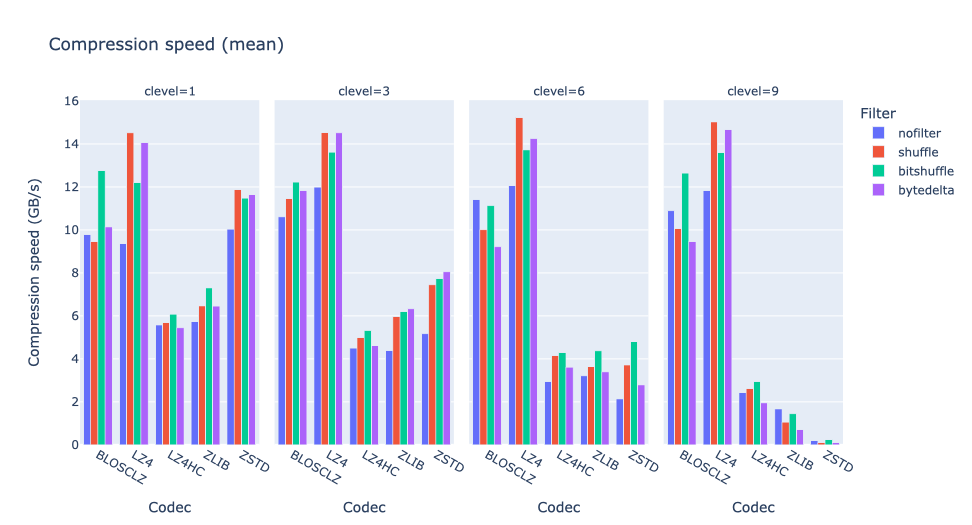
Here one can see that, to achieve the highest compression rates when combined with shuffle and bytedelta, the codecs require significant CPU resources; this is especially noticeable in the zoomed-in view:
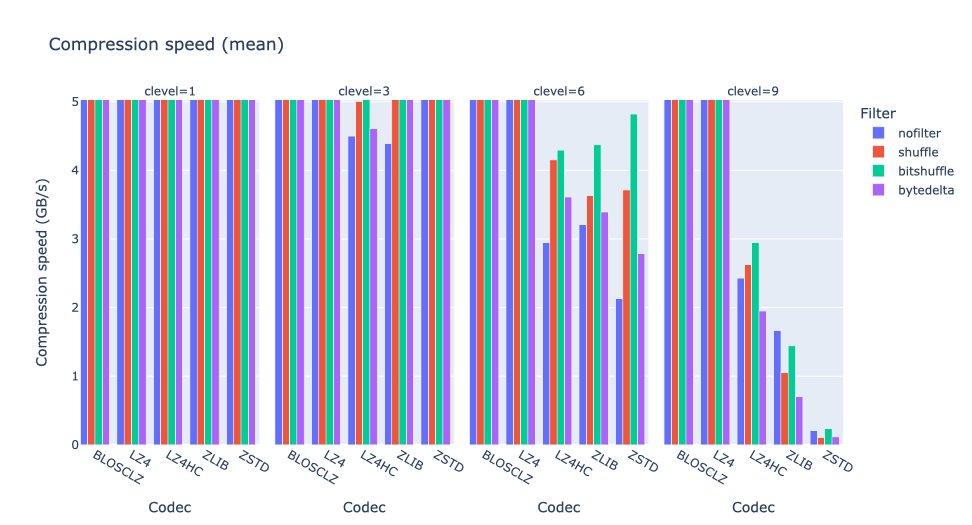
where capable compressors like ZSTD do require up to 2x more time to compress when using bytedelta, especially for high compression levels (6 and 9).
Now, let us examine decompression speeds:
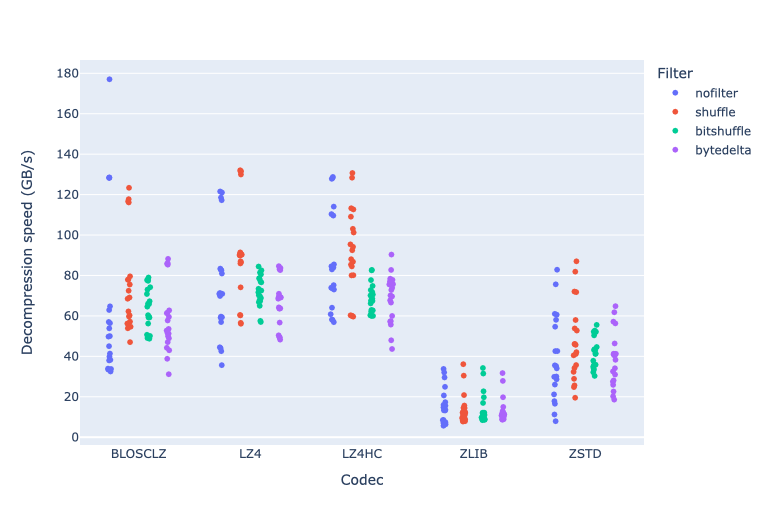
In general, decompression is faster than compression. BLOSCLZ, LZ4 and LZ4HC can achieve over 100 GB/s. BLOSCLZ reaches nearly 180 GB/s using no filters on the snow dataset (lowest complexity).
Let’s see the decompression speed grouped by compression levels:
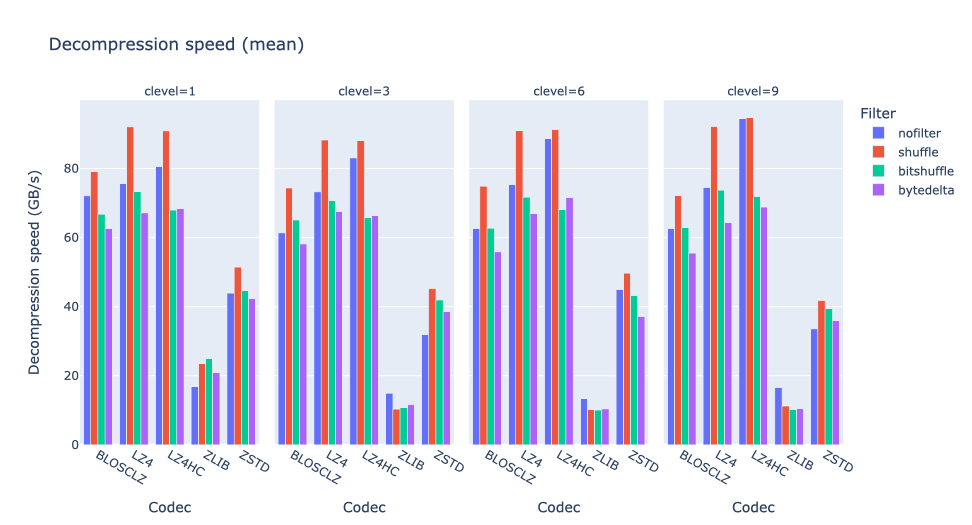
The bytedelta filter noticeably reduces speed for most codecs, up to 20% or more. ZSTD performance is less impacted.
Achieving a balance between compression ratio and speed
Often, you want to achieve a good balance of compression and speed, rather than extreme values of either. We will conclude by showing plots depicting a combination of both metrics and how bytedelta influences them.
Let's first represent the compression ratio versus compression speed:
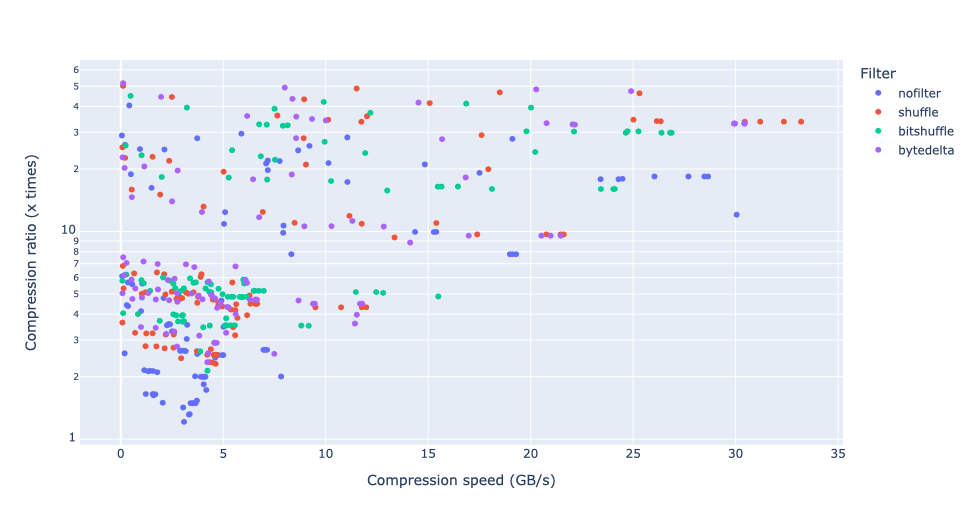
As we can see, the shuffle filter is typically found on the Pareto frontier (in this case, the point furthest to the right and top). Bytedelta comes next. In contrast, not using a filter at all is on the opposite side. This is typically the case for most real-world numerical datasets.
Let's now group filters and datasets and calculate the mean values of combining (in this case, multiplying) the compression ratio and compression speed for all codecs.
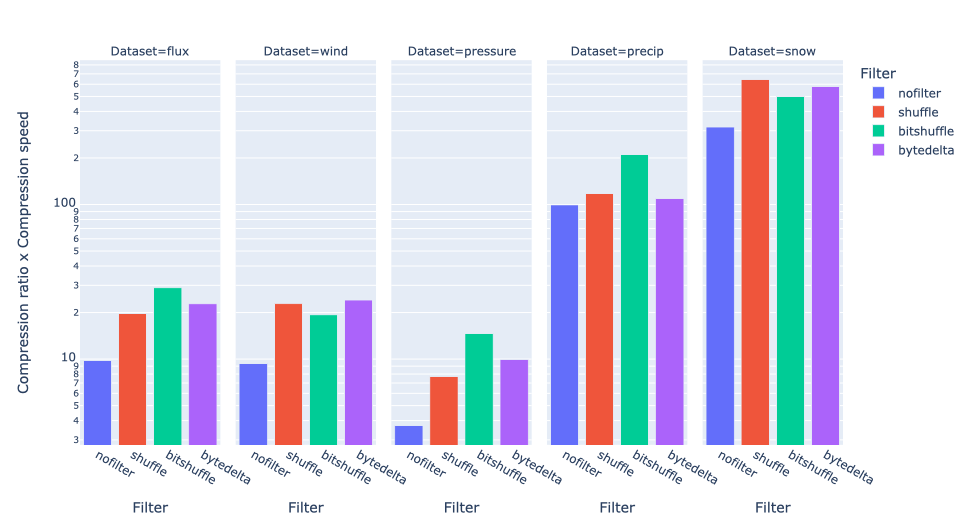
As can be seen, bytedelta works best with the wind dataset (which is quite complex), while bitshuffle does a good job in general for the others. The shuffle filter wins on the snow dataset (low complexity).
If we group by compression level:
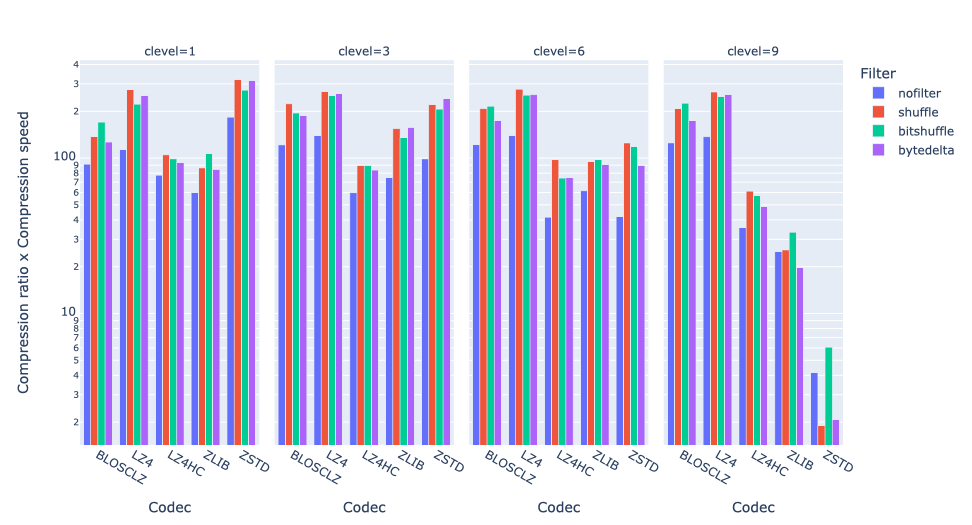
We see that bytedelta works well with LZ4 here, and also with ZSTD at the lowest compression level (1).
Let's revise the compression ratio versus decompression speed comparison:
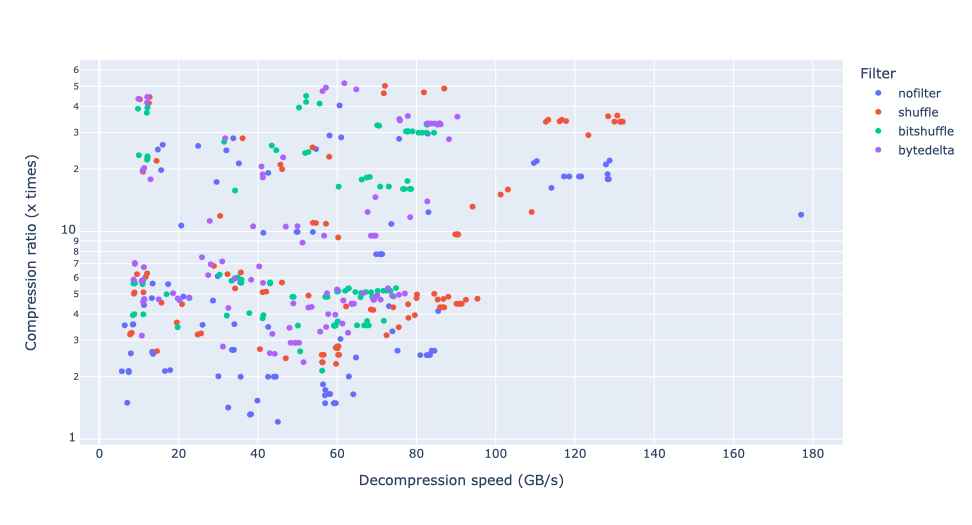
Let's group together the datasets and calculate the mean for all codecs:
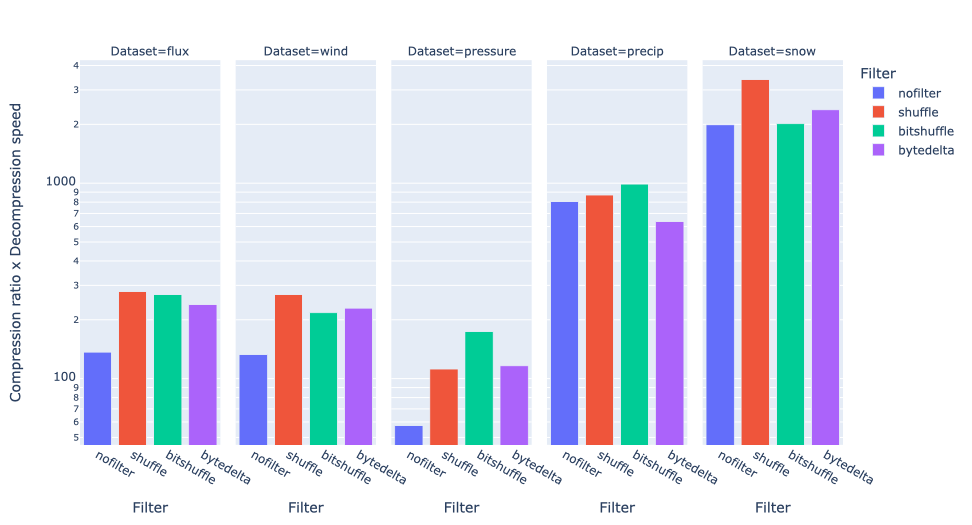
In this case, shuffle generally prevails, with bitshuffle also doing reasonably well, winning on precip and pressure datasets.
Also, let’s group the data by compression level:
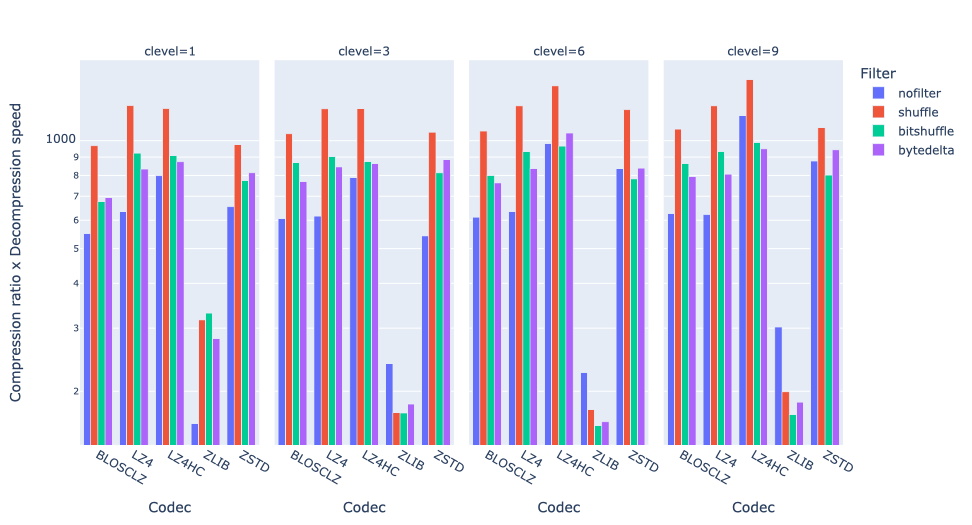
We find that bytedelta compression does not outperform shuffle compression in any scenario. This is unsurprising since decompression is typically fast, and bytedelta's extra processing can decrease performance more easily. We also see that LZ4HC (clevel 6 and 9) + shuffle strikes the best balance in this scenario.
Finally, let's consider the balance between compression ratio, compression speed, and decompression speed:
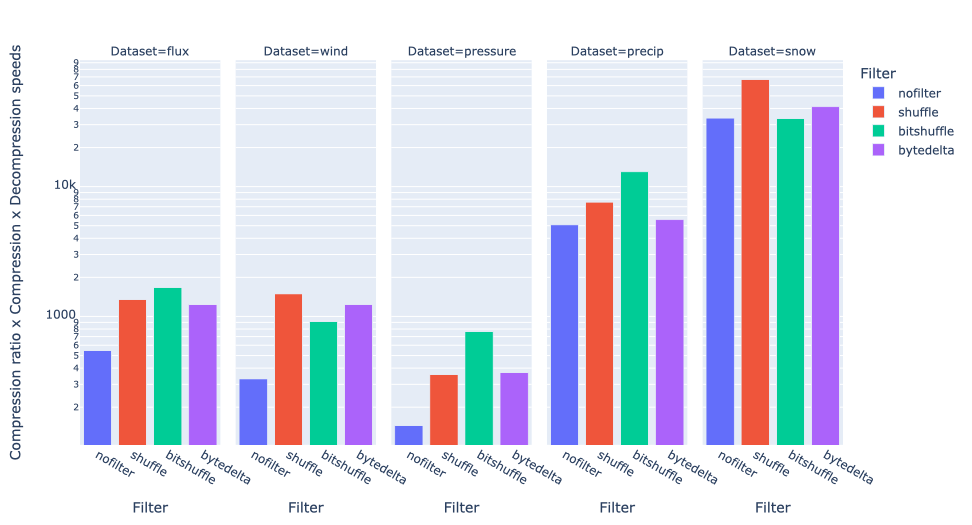
Here the winners are shuffle and bitshuffle, depending on the data set, but bytedelta never wins.
If we group by compression levels:
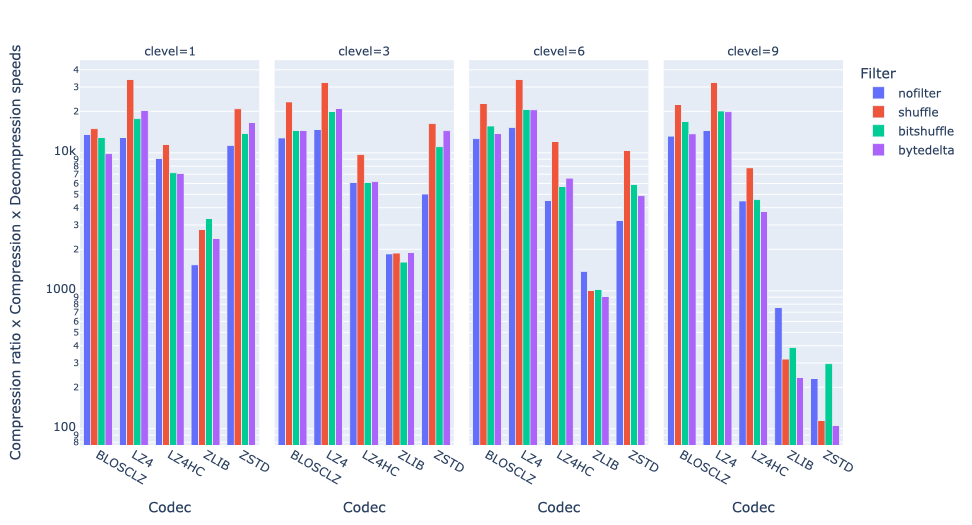
Overall, we see LZ4 as the clear winner at any level, especially when combined with shuffle. On the other hand, bytedelta did not win in any scenario here.
Benchmarks for other computers
We have run the benchmarks presented here in an assortment of different boxes:
Also, find here a couple of runs using the i9-13900K box above, but with the always split and never split settings:
Reproducing the benchmarks is straightforward. First, download the data; the downloaded files will be in the new era5_pds/ directory. Then perform the series of benchmarks; this is takes time, so grab coffee and wait 30 min (fast workstations) to 6 hours (slow laptops). Finally, run the plotting Jupyter notebook to explore your results. If you wish to share your results with the Blosc development team, we will appreciate hearing from you!
Conclusion
Bytedelta can achieve higher compression ratios in most datasets, specially in combination with capable codecs like ZSTD, with a maximum gain of 37% (pressure) over other codecs; only in one case (precip) compression ratio decreases. By compressing data more efficiently, bytedelta can reduce file sizes even more, accelerating transfer and storage.
On the other hand, while bytedelta excels at achieving high compression ratios, this requires more computing power. We have found that for striking a good balance between high compression and fast compression/decompression, other filters, particularly shuffle, are superior overall.
We've learned that no single codec/filter combination is best for all datasets:
ZSTD (clevel 9) + bytedelta can get better absolute compression ratio for most of the datasets.
LZ4 + shuffle is well-balanced for all metrics (compression ratio, speed, decompression speed).
LZ4 (clevel 6) and ZSTD (clevel 1) + shuffle strike a good balance of compression ratio and speed.
LZ4HC (clevel 6 and 9) + shuffle balances well compression ratio and decompression speed.
BLOSCLZ without filters achieves best decompression speed (at least in one instance).
In summary, the optimal choice depends on your priorities.
As a final note, the Blosc development team is working on BTune, a new deep learning tuner for Blosc2. BTune can be trained to automatically recognize different kinds of datasets and choose the optimal codec and filters to achieve the best balance, based on the user's needs. This would create a much more intelligent compressor that can adapt itself to your data faster, without requiring time-consuming manual tuning. If interested, contact us; we are looking for beta testers!
Comments
Comments powered by Disqus