What Is Blosc?
Blosc is a high-performance compressor that has been optimized for binary data. Its design allows for faster transmission of data to the processor cache than the traditional, non-compressed, direct memory fetch approach through an memcpy() OS call. This can be useful not only in reducing the size of large datasets, but also in accelerating I/O, be either on-disk or in-memory (both are supported).
Watch this introductory video to learn more about the main features of Blosc:
Blosc2 is the new iteration of the Blosc 1.x series, which adds more features and better documentation. You can also check out the slides that explain the highlights of Blosc2.
Blosc2 also includes NDim, a container with multi-dimensional capabilities. In particular, Blosc2 NDim excels at reading multi-dimensional slices, thanks to its innovative pineapple-style partitioning. To learn more, watch the video Why slicing in a pineapple-style is useful.
Why It Works?
Blosc uses the blocking technique (as described here) to reduce activity on the memory bus as much as possible. The blocking technique divides datasets into blocks small enough to fit in the caches of modern processors and performs compression/decompression there. It also leverages SIMD (SSE2) and multi-threading capabilities present in modern multi-core processors to accelerate the compression/decompression process to the maximum.
Blosc2 also applies more advanced techniques to improve the compression ratio on sparse datasets, and a larger diversity of filters such as bytedelta. This makes Blosc2 a very versatile compressor that can be used in a wide range of situations.
Performance
Blosc2 is also designed to be efficient when retrieving blocks and chunks in multidimensional datasets. For comparison purposes, see below the speed that BloscLZ, one of the fastest codecs available in Blosc, can achieve when combined with different libraries supporting Blosc(1)/Blosc2 when accessing a 7.3 TB dataset:
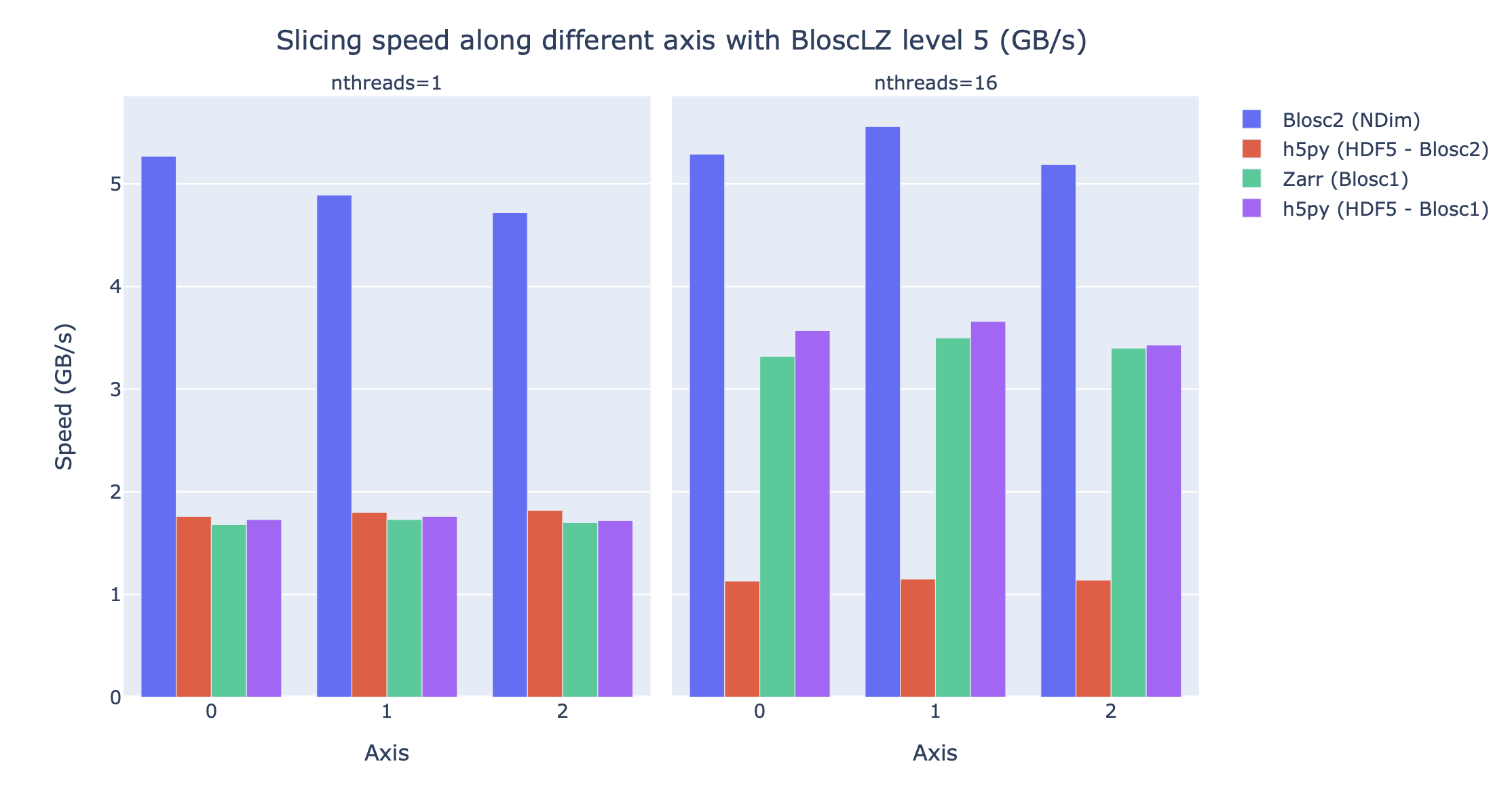
Note how BloscLZ does not need a lot of threads to reach its performance. Such a low requirement on CPU core count makes it ideal for running on small laptops while guaranteeing reasonable performance.
And below is the compression ratio that BloscLZ, and also Zstd (the codec that can typically achieve better compression ratios in Blosc), can achieve when combined with different libraries supporting Blosc(1)/Blosc2:
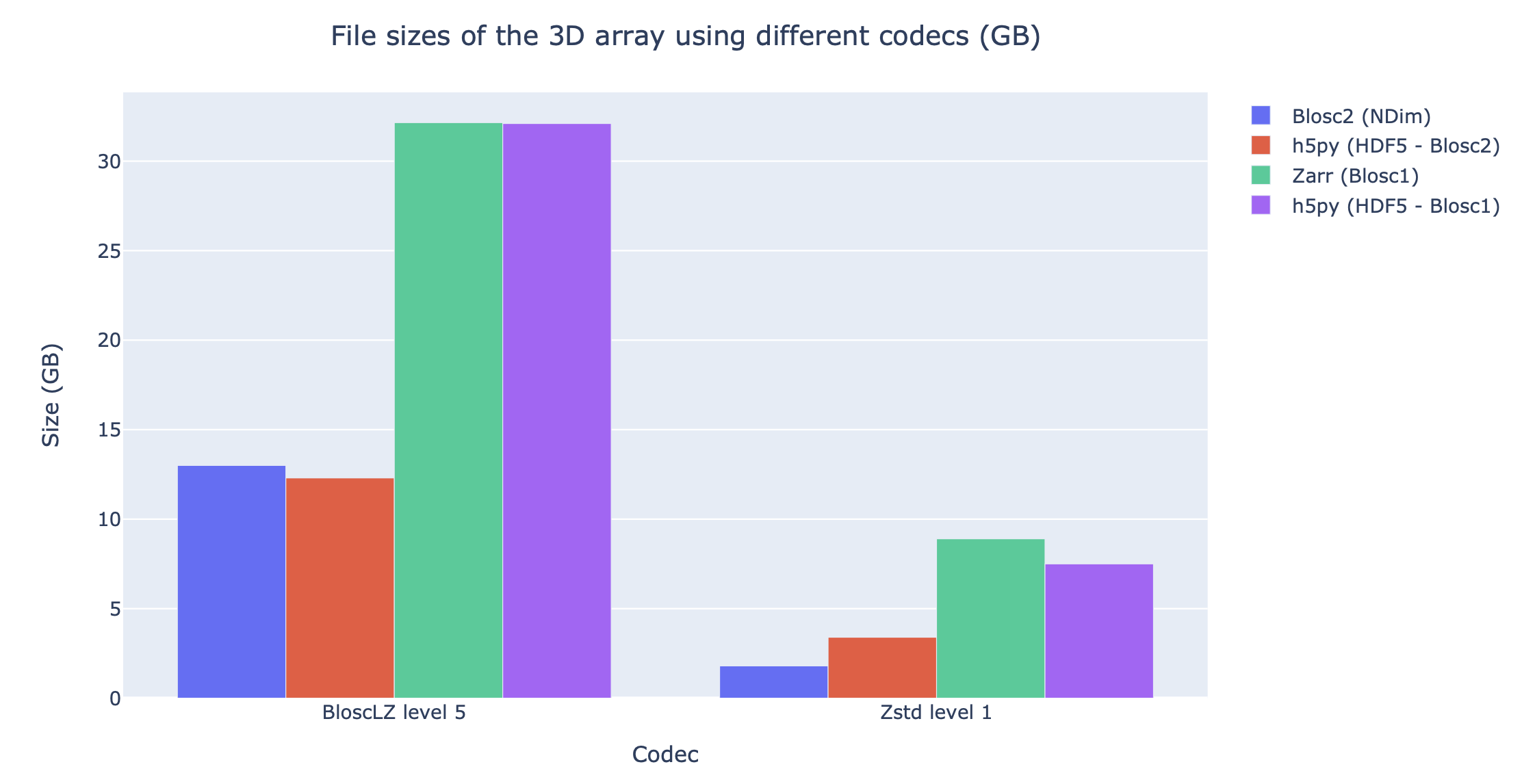
See how Blosc2 can make better use of the space required to store the compressed data and internal indices, specially when dealing with sparse datasets (as is the case above). More info in these slides.
You can find more benchmarks on our blog. Additionally, you may be interested in reading this article on Breaking Down Memory Walls. Finally, make sure to check out Blosc2, the next generation of Blosc, with support for n-dimensional data as well as more efficient handling of sparse data.
Fully Documented Format
Blosc2 is an open and fully documented format. All the documentation take less than 1000 lines of text, and it should be easy to understand and implement, so you are not locked-in to a proprietary (or difficult to replicate) format.
Blosc1 is also completely documented, although all the action and development efforts are now mostly happening in Blosc2. If you are looking for a stable and long-term solution, Blosc2 is the way to go.
Blosc as a Meta-Compressor
Blosc is not like other compressors; it should rather be called a meta-compressor. This is because it can use different codecs (libraries that reduce the size of inputs) and filters (libraries that improve compression ratio) under the hood. Nonetheless, it can still be referred to as a compressor because it includes several codecs conveniently packaged and made accessible for you.
Currently, Blosc uses BloscLZ by default, a codec heavily based on FastLZ. Blosc also includes support for LZ4 and LZ4HC, Zlib and Zstd right out-of-the-box. Also, it comes with highly optimized shuffle, bitshuffle, bytedelta and precision truncation filters. These can use SSE2, AVX2 (Intel), NEON (ARM) or VMX/AltiVec/VSX (PowerPC) instructions (if available).
Blosc is responsible for coordinating codecs and filters to leverage the blocking technique (described above) and multi-threaded execution (when several cores are available), while making minimal use of temporary buffers. This ensures that every codec and filter can operate at high speeds, even if it was not initially designed for blocking or multi-threading. For instance, Blosc allows the use of the LZ4 codec in a multi-threaded manner by default.
Other Advantages over Existing Compressors
Meant for binary data: Can take advantage of the type size meta-information to improve the compression ratio by using the integrated shuffle and bitshuffle filters.
Small overhead on non-compressible data: Only a maximum of 32 bytes for Blosc2 (16 for Blosc1) per data chunk are needed on non-compressible data.
63-bit containers: In Blosc2, we have introduced super-chunks as a way to overcome the limitations of chunks, which can only be up to 2^31 bytes in size. Super-chunks, on the other hand, can host data up to 2^63 bytes in size.
Frames: Blosc2 also has introduced a way to serialize data either in-memory or on-disk. Frames provide an efficient way to persist or transmit the data in a compressed format.
However, there is much more to Blosc. For an updated list of features, please refer to our ROADMAP and recent progress reports. When combined, these features distinguish Blosc from other similar solutions.
Cooperation with Other Libraries
Although Blosc is designed to be used alone, its comprehensive C and Python APIs makes it easy to be used in combination with other libraries as well. Actually, the Blosc development team has been working hard to make Blosc2 a very versatile compressor that can be used in a wide range of situations.
For instance, when used with HDF5/PyTables, Blosc2 can help to query tables with 100 trillion rows in human time frames. Also, its integration with PyTables allows to compress and store persistently 7.3 TB of data coming from 500 million of stars in the Milky Way in just 8 GB (yes, a compress ratio of almost 1000x), and query it in a very efficient way.
Moreover, h5py can use Blosc/Blosc2 too via hdf5plugin. In particular, there is b2h5py, which seeks a tighter integration of Blosc2 and h5py. All of these projects come with binary wheels, so it is easy to start hacking with them. As you can see, the cooperation of Blosc and HDF5 formats is particularly strong. Read more on this integration (besides other bells and whistles) in this report.
Other projects that benefit from using Blosc are Zarr, ADIOS2 and JNifti, a NIfTI JSON-wrapper for storing neuroimaging data. This is just a small sample of the many projects that can benefit from using Blosc/Blosc2.
Where Can Blosc Be Used?
Provided that data is compressible enough, applications that use Blosc are expected to surpass expected physical limits for I/O performance, either for network, disk, or in-memory storage, simply because applications needs to transmit less (compressed) data, and compression/decompression is very fast and usually happens entirely in CPU caches. For instance, see how Blosc can break down memory walls.
Blosc2 also adds support for sparse and multi-dimensional datasets, which are common in scientific applications. See an example on how Blosc can make an efficient access to much larger datasets than the available memory.
Adapting Blosc to your needs
We understand that every user has unique needs, so we have made it possible to register your own codecs and filters to better adapt Blosc to different scenarios. Additionally, you can request that they be included in the main C-Blosc2 library, which not only allows for easier deployment, but also contributes to creating a richer and more useful ecosystem.
Additionally, ironArray SLU created Btune, an innovative deep learning tool that can automatically determine the best compression parameters for your specific use case. The ironArray team is continuously working on improving it, and provides commercial support to ensure that it meets your needs.
Is Blosc Ready for Production Use?
Yes, it is!
Blosc is currently being used in various libraries and is able to compress data at a rate that exceeds several petabytes per month worldwide. Fortunately, there haven't been many reports of failures caused by Blosc itself, but we strive to respond as quickly as possible when such issues do arise.
After a long period of testing, C-Blosc2 has entered the production stage in version 2.0.0. Additionally, all new releases are guaranteed to read from persistent storage generated from previous releases (as of 2.0.0).
Git repository, downloads and ticketing
The home of the git repository for all Blosc-related libraries is located at:
You can download the sources and file tickets there too.
Mastodon feed
Keep informed about the latest developments by following the @Blosc2 mastodon account:
Mailing list
There is an official Blosc blosc mailing list at:
Python wrappers
The official Python wrappers can be found at:
http://github.com/Blosc/python-blosc http://github.com/Blosc/python-blosc2
Want To Contribute?
Your contribution is crucial to making Blosc as solid as possible. If you detect a bug or wish to propose an enhancement, feel free to open a new ticket or make yourself heard on the mailing list. Also, please note that we have a Code of Conduct that you should read before contributing in any way.
If you like Blosc and want to support our mission, please consider making a donation to support our efforts.
Blosc License
Blosc is a free software released under the permissive BSD license. This means that you can use it in almost any way you want!
Sponsors
Blosc and Blosc2 have been developed with the support of several organizations. We would like to thank them for their support.
Blosc is a fiscally sponsored project of NumFOCUS, a nonprofit dedicated to supporting the open source scientific computing community. If you like Blosc and want to support our mission, please consider making a donation to support our efforts.

Commercial Support
ironArray SLU provides data-driven solutions and consulting services around compression for binary data and is a principal and proud sponsor of Blosc. The ironArray team is mostly the same creators of the Blosc, PyTables and numexpr projects. Contact them if you need help with your data compression/management needs.
-- The Blosc Development Team