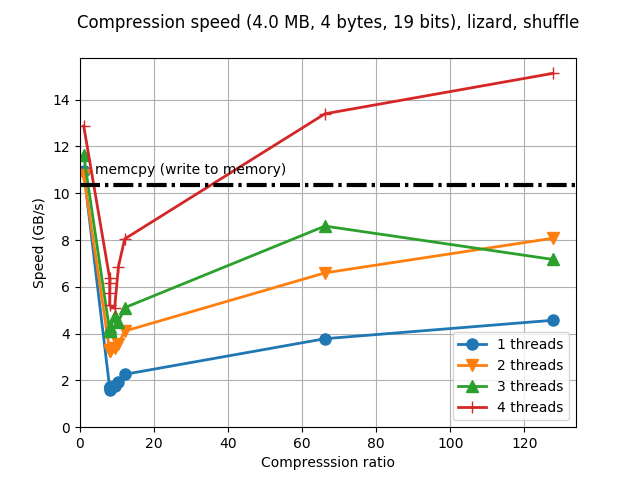
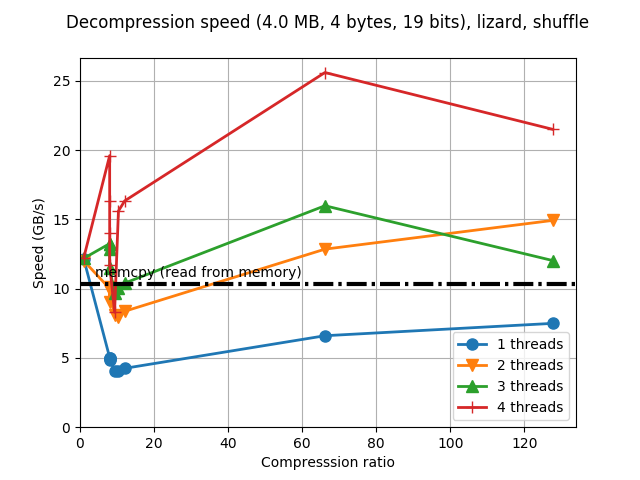
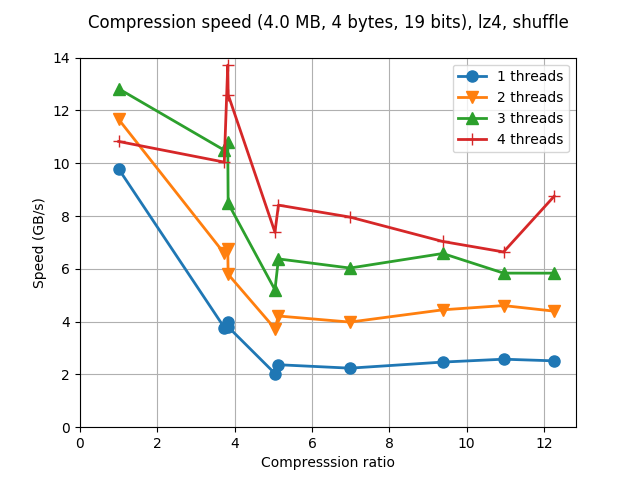
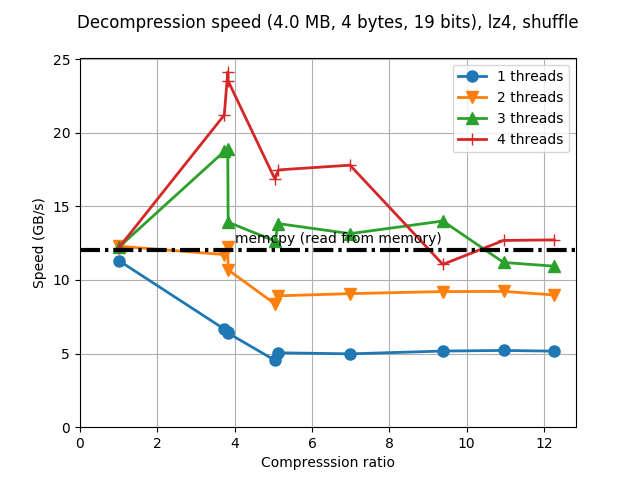
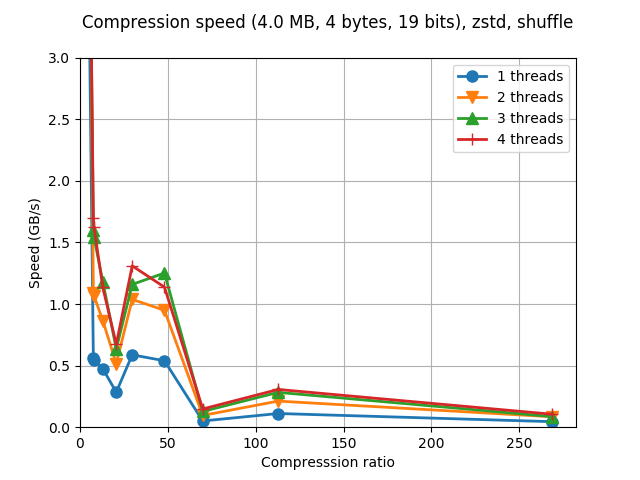
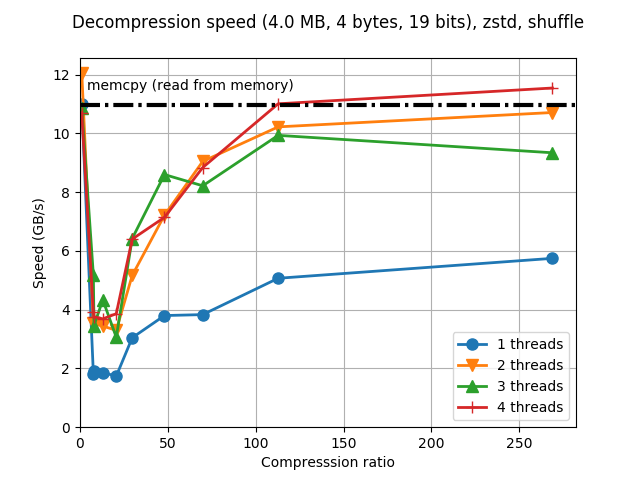
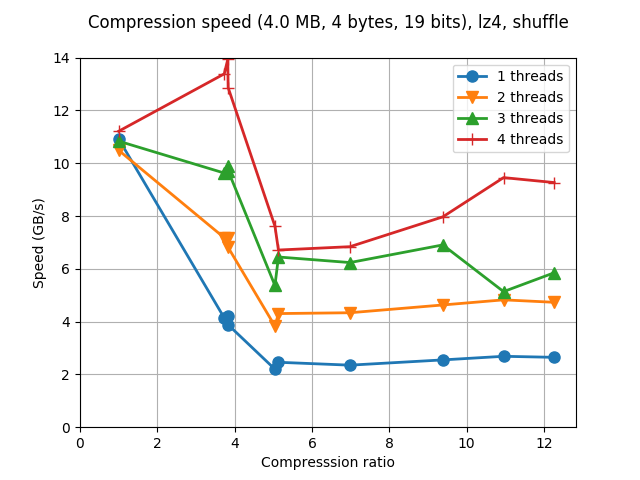
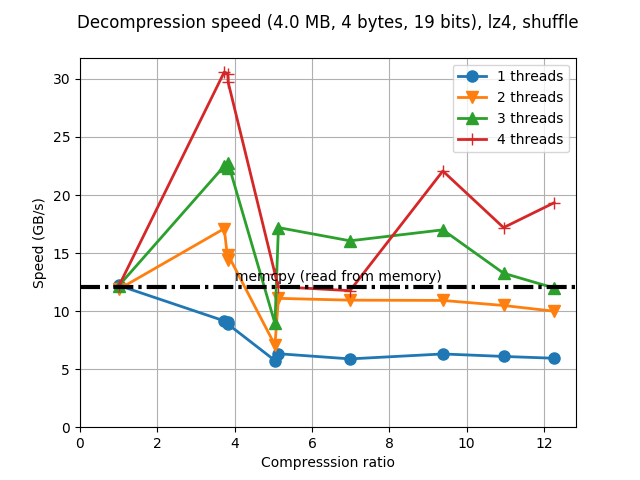
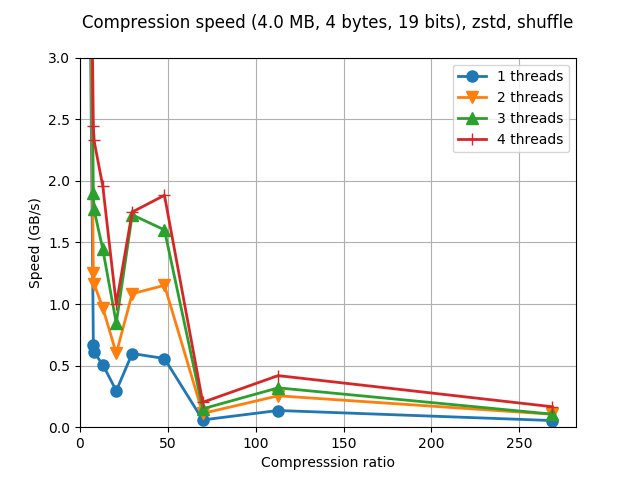
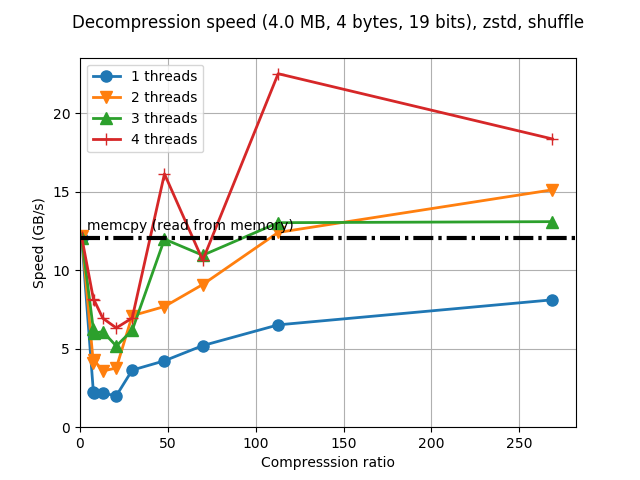
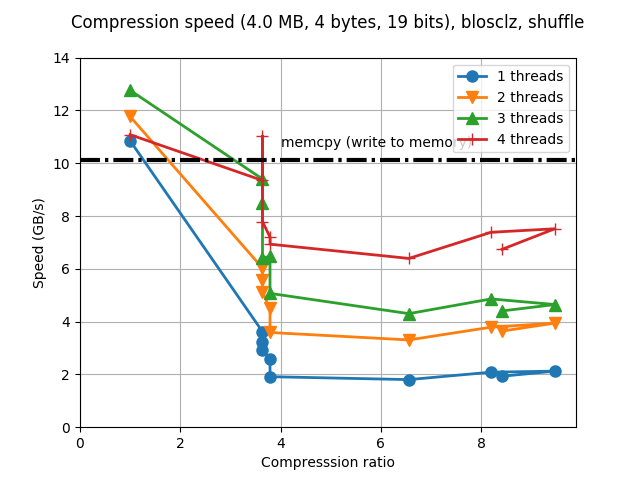
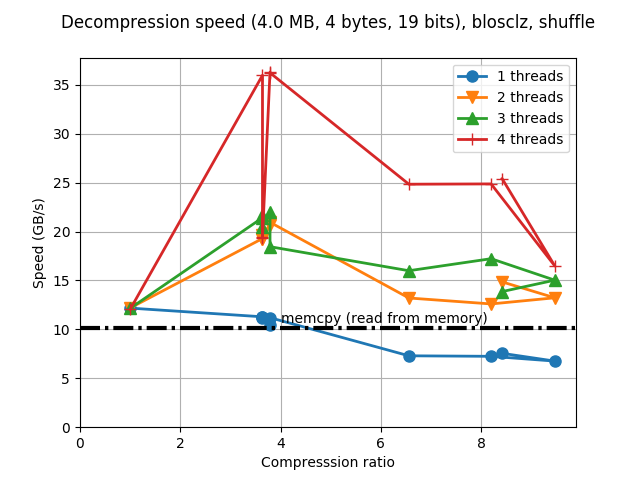
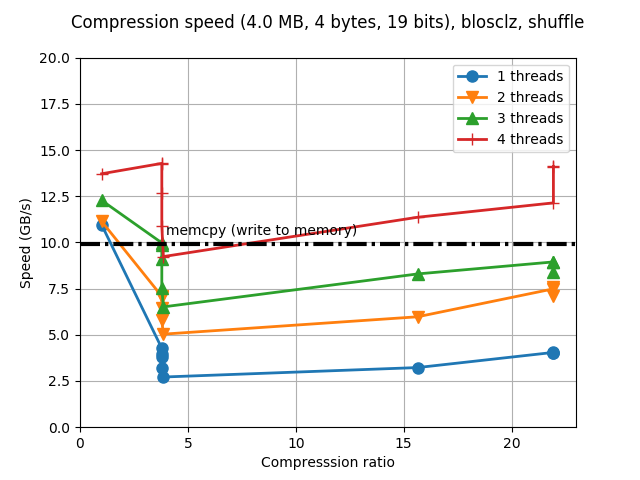
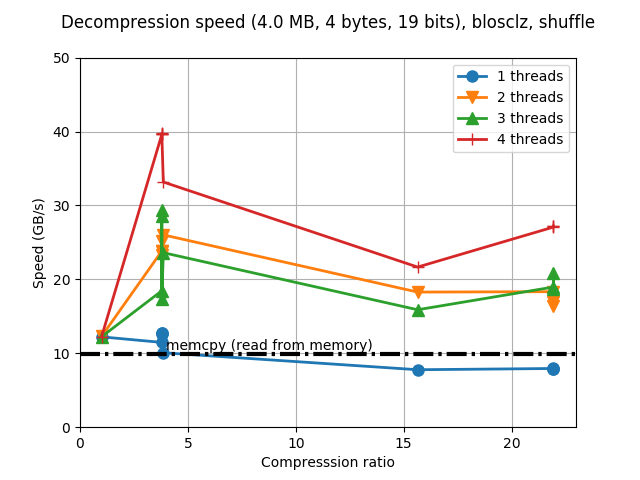
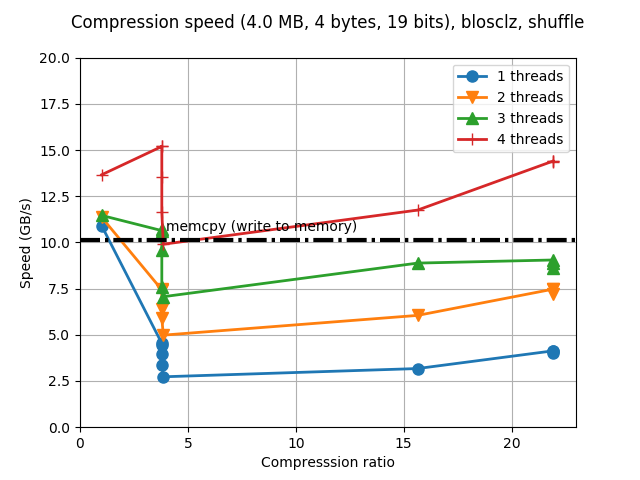
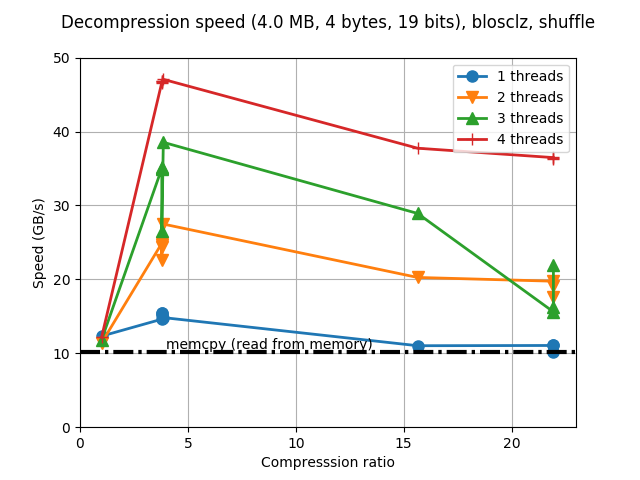
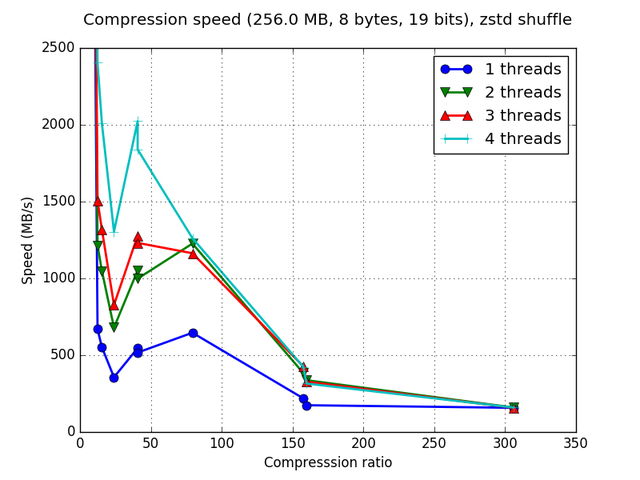
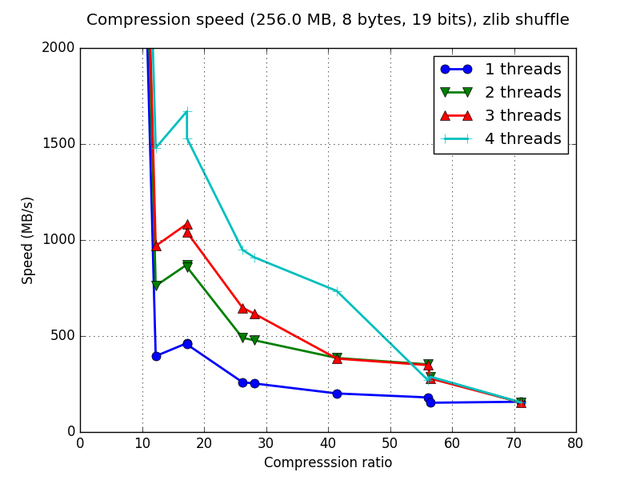
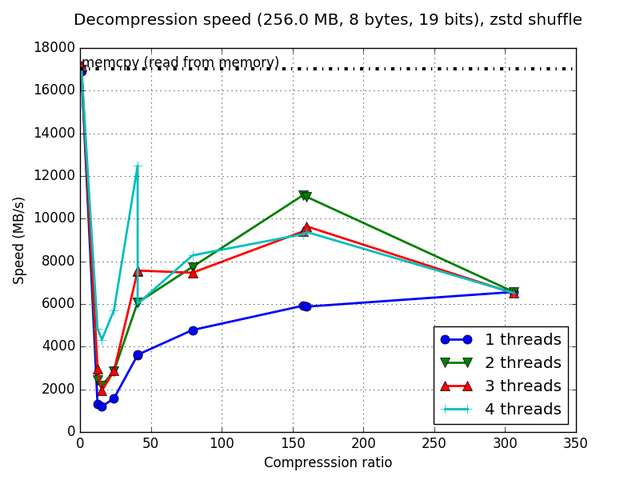
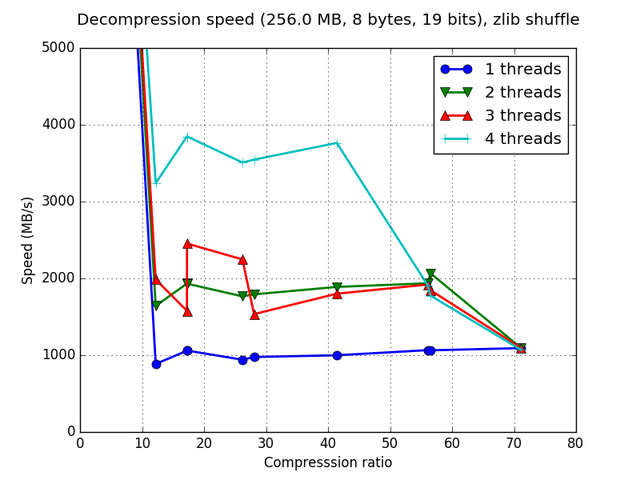
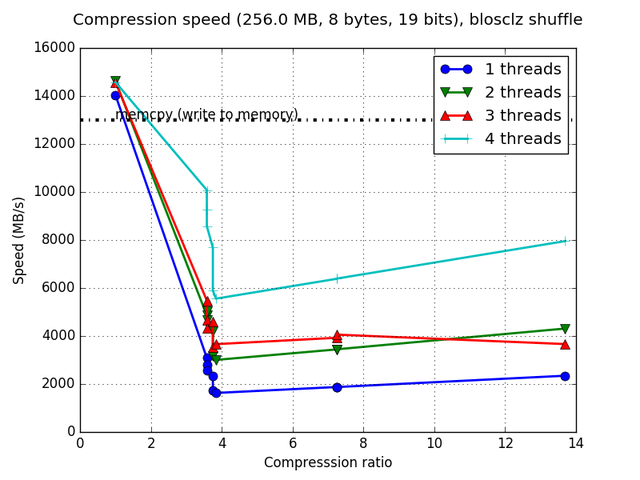
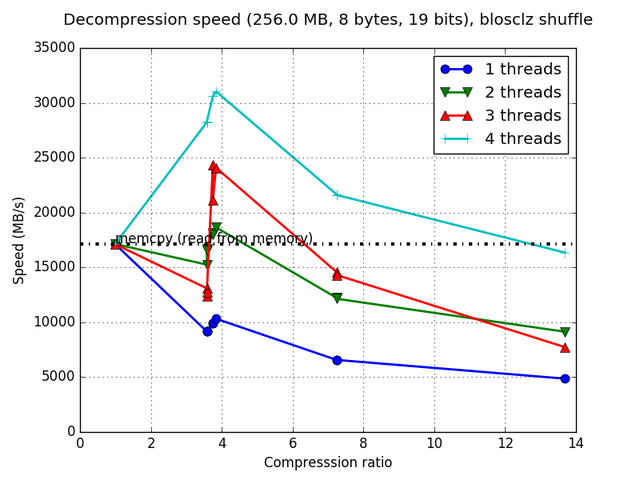
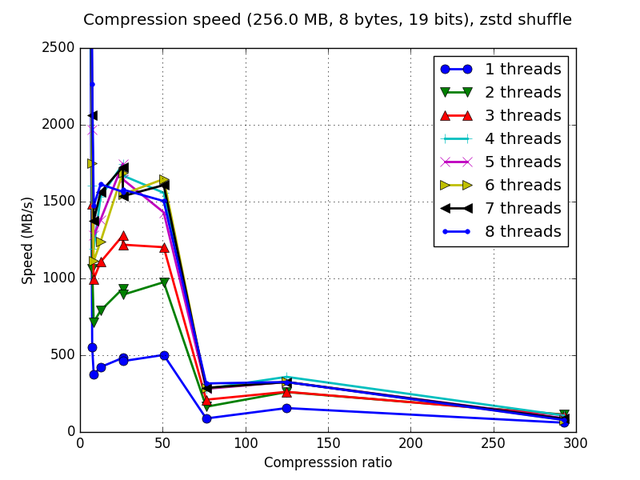
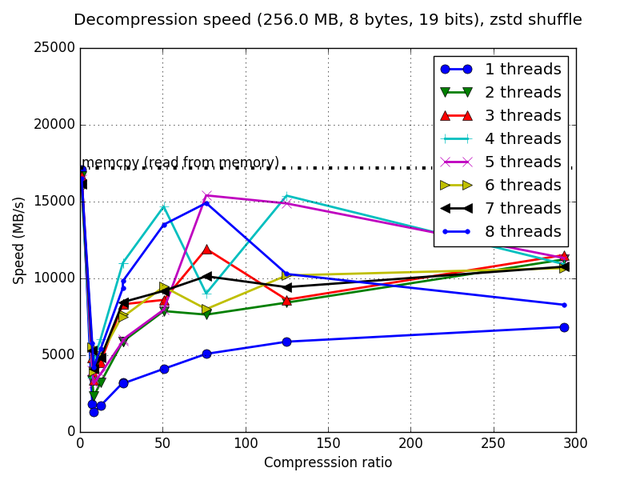
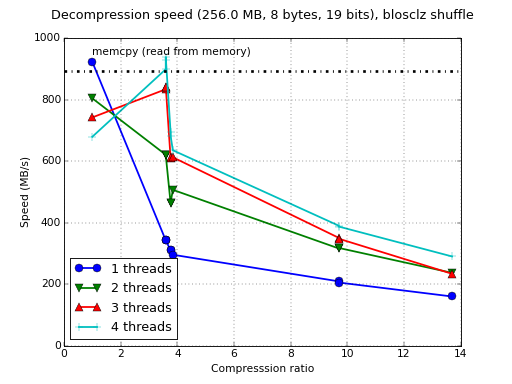
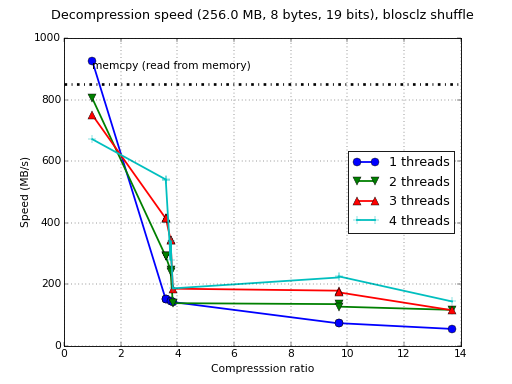
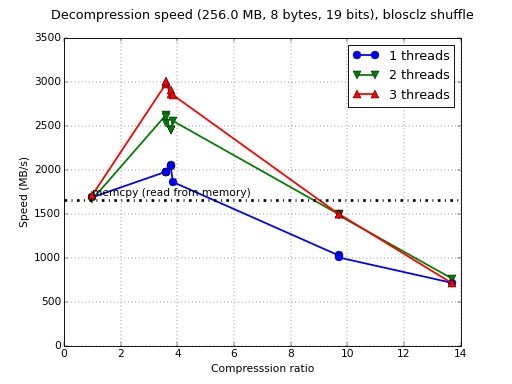
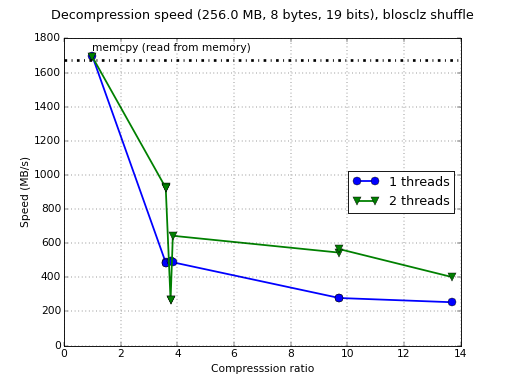
Although Blosc was meant for hosting more than one filter since day 0,
it has traditionally came with just a single filter, known as
'shuffle', meant for shuffling bytes in binary blocks. Today this has
changed, and c-blosc has officially received a new filter called
'bitshuffle' (a backport of the one included in the
bithsuffle project).
And you guess it, it works in a very similar way than
'shuffle', just that the shuffling happens at the bit level and not at
the byte one.
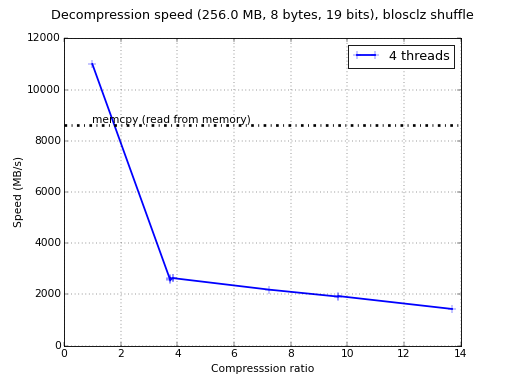
Just for whetting your appetite here there are some small synthetic
benchmarks on what you can expect from the newcomer. I'll start using
my own laptop (Intel i5-3380M @ 2.90GHz, GCC 4.9.1, Ubuntu 14.10) and
showing how the benchmark that comes with c-blosc performs with the
LZ4 compressor and the regular 'shuffle' filter:
$ bench/bench lz4 shuffle single 2
Blosc version: 1.7.0.dev ($Date:: 2015-05-27 #$)
List of supported compressors in this build: blosclz,lz4,lz4hc,snappy,zlib
Supported compression libraries:
BloscLZ: 1.0.5
LZ4: 1.7.0
Snappy: 1.1.1
Zlib: 1.2.8
Using compressor: lz4
Using shuffle type: shuffle
Running suite: single
--> 2, 2097152, 8, 19, lz4, shuffle
********************** Run info ******************************
Blosc version: 1.7.0.dev ($Date:: 2015-05-27 #$)
Using synthetic data with 19 significant bits (out of 32)
Dataset size: 2097152 bytes Type size: 8 bytes
Working set: 256.0 MB Number of threads: 2
********************** Running benchmarks *********************
memcpy(write): 529.1 us, 3780.3 MB/s
memcpy(read): 245.6 us, 8143.4 MB/s
Compression level: 0
comp(write): 267.3 us, 7483.3 MB/s Final bytes: 2097168 Ratio: 1.00
decomp(read): 200.0 us, 9997.5 MB/s OK
Compression level: 1
comp(write): 462.8 us, 4321.1 MB/s Final bytes: 554512 Ratio: 3.78
decomp(read): 246.6 us, 8111.5 MB/s OK
Compression level: 2
comp(write): 506.6 us, 3947.7 MB/s Final bytes: 498960 Ratio: 4.20
decomp(read): 331.9 us, 6025.1 MB/s OK
Compression level: 3
comp(write): 486.8 us, 4108.8 MB/s Final bytes: 520824 Ratio: 4.03
decomp(read): 233.5 us, 8565.2 MB/s OK
Compression level: 4
comp(write): 497.9 us, 4017.0 MB/s Final bytes: 332112 Ratio: 6.31
decomp(read): 258.3 us, 7743.8 MB/s OK
Compression level: 5
comp(write): 474.6 us, 4214.5 MB/s Final bytes: 327112 Ratio: 6.41
decomp(read): 287.8 us, 6949.0 MB/s OK
Compression level: 6
comp(write): 558.0 us, 3584.4 MB/s Final bytes: 226308 Ratio: 9.27
decomp(read): 284.8 us, 7022.7 MB/s OK
Compression level: 7
comp(write): 689.9 us, 2899.1 MB/s Final bytes: 211880 Ratio: 9.90
decomp(read): 363.0 us, 5509.1 MB/s OK
Compression level: 8
comp(write): 691.9 us, 2890.6 MB/s Final bytes: 220464 Ratio: 9.51
decomp(read): 385.5 us, 5188.5 MB/s OK
Compression level: 9
comp(write): 567.0 us, 3527.6 MB/s Final bytes: 132154 Ratio: 15.87
decomp(read): 627.3 us, 3188.2 MB/s OK
Round-trip compr/decompr on 7.5 GB
Elapsed time: 3.6 s, 4755.3 MB/s
Now, look at what bitshuffle can do with the same datasets and compressor:
$ bench/bench lz4 bitshuffle single 2
Blosc version: 1.7.0.dev ($Date:: 2015-05-27 #$)
List of supported compressors in this build: blosclz,lz4,lz4hc,snappy,zlib
Supported compression libraries:
BloscLZ: 1.0.5
LZ4: 1.7.0
Snappy: 1.1.1
Zlib: 1.2.8
Using compressor: lz4
Using shuffle type: bitshuffle
Running suite: single
--> 2, 2097152, 8, 19, lz4, bitshuffle
********************** Run info ******************************
Blosc version: 1.7.0.dev ($Date:: 2015-05-27 #$)
Using synthetic data with 19 significant bits (out of 32)
Dataset size: 2097152 bytes Type size: 8 bytes
Working set: 256.0 MB Number of threads: 2
********************** Running benchmarks *********************
memcpy(write): 518.5 us, 3857.3 MB/s
memcpy(read): 248.6 us, 8045.7 MB/s
Compression level: 0
comp(write): 259.5 us, 7706.1 MB/s Final bytes: 2097168 Ratio: 1.00
decomp(read): 217.5 us, 9196.3 MB/s OK
Compression level: 1
comp(write): 1099.0 us, 1819.9 MB/s Final bytes: 72624 Ratio: 28.88
decomp(read): 824.2 us, 2426.5 MB/s OK
Compression level: 2
comp(write): 1093.2 us, 1829.5 MB/s Final bytes: 71376 Ratio: 29.38
decomp(read): 1293.2 us, 1546.5 MB/s OK
Compression level: 3
comp(write): 1084.5 us, 1844.2 MB/s Final bytes: 69200 Ratio: 30.31
decomp(read): 1331.2 us, 1502.4 MB/s OK
Compression level: 4
comp(write): 1193.2 us, 1676.2 MB/s Final bytes: 42480 Ratio: 49.37
decomp(read): 833.8 us, 2398.7 MB/s OK
Compression level: 5
comp(write): 1190.9 us, 1679.4 MB/s Final bytes: 42928 Ratio: 48.85
decomp(read): 880.2 us, 2272.2 MB/s OK
Compression level: 6
comp(write): 969.7 us, 2062.5 MB/s Final bytes: 32000 Ratio: 65.54
decomp(read): 854.8 us, 2339.8 MB/s OK
Compression level: 7
comp(write): 1056.2 us, 1893.6 MB/s Final bytes: 40474 Ratio: 51.81
decomp(read): 960.8 us, 2081.7 MB/s OK
Compression level: 8
comp(write): 1018.5 us, 1963.8 MB/s Final bytes: 28050 Ratio: 74.76
decomp(read): 966.8 us, 2068.7 MB/s OK
Compression level: 9
comp(write): 1161.7 us, 1721.6 MB/s Final bytes: 25188 Ratio: 83.26
decomp(read): 1245.5 us, 1605.8 MB/s OK
Round-trip compr/decompr on 7.5 GB
Elapsed time: 7.8 s, 2161.7 MB/s
Amazing! the compression ratios are much higher (up to 83x vs 16x)
which is very exciting. The drawback is that with 'bitshuffle' the
compression/decompression speed is between 2x and 4x slower than with
the regular 'shuffle'. In fact, this slowdown is unusually light
because the additional work should be much more (1 byte has 8 bits),
so that's not too bad.
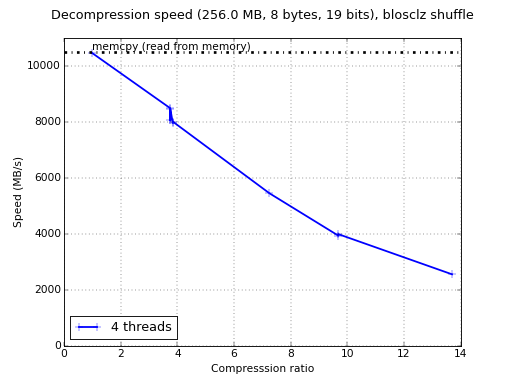
But we have some good news: besides SSE2, 'bitshuffle' also supports
AVX2 SIMD instructions (as 'shuffle' itself) but unfortunately my
laptop does not have them (pre-Haswell). So let's run the benchmark
above in a AVX2 server (Intel Xeon E3-1240 v3 @ 3.40GHz, GCC 4.9.3,
Gentoo 2.2):
$ bench/bench lz4 bitshuffle single 8
Blosc version: 1.7.0.dev ($Date:: 2015-05-27 #$)
List of supported compressors in this build: blosclz,lz4,lz4hc,snappy,zlib
Supported compression libraries:
BloscLZ: 1.0.5
LZ4: 1.7.0
Snappy: 1.1.1
Zlib: 1.2.8
Using compressor: lz4
Using shuffle type: bitshuffle
Running suite: single
--> 8, 2097152, 8, 19, lz4, bitshuffle
********************** Run info ******************************
Blosc version: 1.7.0.dev ($Date:: 2015-05-27 #$)
Using synthetic data with 19 significant bits (out of 32)
Dataset size: 2097152 bytes Type size: 8 bytes
Working set: 256.0 MB Number of threads: 8
********************** Running benchmarks *********************
memcpy(write): 264.9 us, 7551.1 MB/s
memcpy(read): 174.1 us, 11488.6 MB/s
Compression level: 0
comp(write): 173.1 us, 11551.7 MB/s Final bytes: 2097168 Ratio: 1.00
decomp(read): 119.3 us, 16765.2 MB/s OK
Compression level: 1
comp(write): 271.8 us, 7358.1 MB/s Final bytes: 72624 Ratio: 28.88
decomp(read): 225.7 us, 8862.7 MB/s OK
Compression level: 2
comp(write): 275.7 us, 7253.7 MB/s Final bytes: 71376 Ratio: 29.38
decomp(read): 229.2 us, 8724.8 MB/s OK
Compression level: 3
comp(write): 274.5 us, 7285.9 MB/s Final bytes: 69200 Ratio: 30.31
decomp(read): 238.8 us, 8374.6 MB/s OK
Compression level: 4
comp(write): 249.5 us, 8015.5 MB/s Final bytes: 42480 Ratio: 49.37
decomp(read): 229.8 us, 8701.6 MB/s OK
Compression level: 5
comp(write): 249.1 us, 8028.1 MB/s Final bytes: 42928 Ratio: 48.85
decomp(read): 243.9 us, 8198.8 MB/s OK
Compression level: 6
comp(write): 332.4 us, 6017.5 MB/s Final bytes: 32000 Ratio: 65.54
decomp(read): 322.2 us, 6206.4 MB/s OK
Compression level: 7
comp(write): 431.9 us, 4630.2 MB/s Final bytes: 40474 Ratio: 51.81
decomp(read): 437.6 us, 4570.7 MB/s OK
Compression level: 8
comp(write): 421.5 us, 4745.0 MB/s Final bytes: 28050 Ratio: 74.76
decomp(read): 437.2 us, 4574.5 MB/s OK
Compression level: 9
comp(write): 941.1 us, 2125.2 MB/s Final bytes: 25188 Ratio: 83.26
decomp(read): 674.7 us, 2964.2 MB/s OK
Round-trip compr/decompr on 7.5 GB
Elapsed time: 2.8 s, 6047.8 MB/s
Wow, in this case we are having compression speed peaks even higher
than a memcpy (8 GB/s vs 7.5 GB/s), and decompression speed is pretty
good too (8.8 GB/s vs 11.5 GB/s memcpy). With AVX2 support,
'bitshuffle' does have a pretty good performance. But yeah, this
server has 8 physical cores, so we are not actually comparing pears
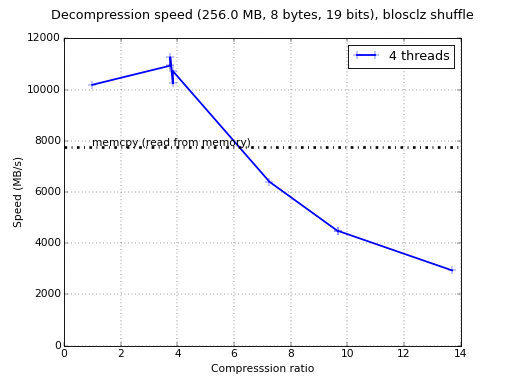
with pears. So let's re-run the benchmark with just 2 threads:
$ bench/bench lz4 bitshuffle single 2
Blosc version: 1.7.0.dev ($Date:: 2015-05-27 #$)
List of supported compressors in this build: blosclz,lz4,lz4hc,snappy,zlib
Supported compression libraries:
BloscLZ: 1.0.5
LZ4: 1.7.0
Snappy: 1.1.1
Zlib: 1.2.8
Using compressor: lz4
Using shuffle type: bitshuffle
Running suite: single
--> 2, 2097152, 8, 19, lz4, bitshuffle
********************** Run info ******************************
Blosc version: 1.7.0.dev ($Date:: 2015-05-27 #$)
Using synthetic data with 19 significant bits (out of 32)
Dataset size: 2097152 bytes Type size: 8 bytes
Working set: 256.0 MB Number of threads: 2
********************** Running benchmarks *********************
memcpy(write): 253.9 us, 7877.5 MB/s
memcpy(read): 174.1 us, 11488.8 MB/s
Compression level: 0
comp(write): 133.4 us, 14995.6 MB/s Final bytes: 2097168 Ratio: 1.00
decomp(read): 117.5 us, 17026.6 MB/s OK
Compression level: 1
comp(write): 604.1 us, 3310.7 MB/s Final bytes: 72624 Ratio: 28.88
decomp(read): 431.2 us, 4638.3 MB/s OK
Compression level: 2
comp(write): 624.3 us, 3203.5 MB/s Final bytes: 71376 Ratio: 29.38
decomp(read): 452.3 us, 4421.5 MB/s OK
Compression level: 3
comp(write): 623.7 us, 3206.8 MB/s Final bytes: 69200 Ratio: 30.31
decomp(read): 442.3 us, 4521.9 MB/s OK
Compression level: 4
comp(write): 585.2 us, 3417.6 MB/s Final bytes: 42480 Ratio: 49.37
decomp(read): 395.3 us, 5058.9 MB/s OK
Compression level: 5
comp(write): 530.0 us, 3773.4 MB/s Final bytes: 42928 Ratio: 48.85
decomp(read): 400.5 us, 4994.0 MB/s OK
Compression level: 6
comp(write): 542.6 us, 3686.0 MB/s Final bytes: 32000 Ratio: 65.54
decomp(read): 426.7 us, 4687.2 MB/s OK
Compression level: 7
comp(write): 605.6 us, 3302.4 MB/s Final bytes: 40474 Ratio: 51.81
decomp(read): 494.5 us, 4044.5 MB/s OK
Compression level: 8
comp(write): 588.1 us, 3400.7 MB/s Final bytes: 28050 Ratio: 74.76
decomp(read): 487.3 us, 4104.6 MB/s OK
Compression level: 9
comp(write): 692.5 us, 2888.2 MB/s Final bytes: 25188 Ratio: 83.26
decomp(read): 591.4 us, 3381.8 MB/s OK
Round-trip compr/decompr on 7.5 GB
Elapsed time: 3.9 s, 4294.1 MB/s
Now, for 2 threads we are getting times that are about 2x slower than
for 8 threads. But the interesting thing here is that the compression
speed is still ~2x faster than my laptop (peaks at 3.7 GB/s vs 1.8
GB/s) and the same goes for decompression (peaks at 5 GB/s vs 2.4
GB/s). Agreed, the server can run at 3.4GHz vs 2.9 GHz of my laptop,
but this alone cannot explain the difference in speed, so the big
responsible for the speedup is the AVX2 support in 'bitshuffle'.
In summary, the new 'bitshuffle' filter is very good news for the
users of the Blosc ecosystem because it adds yet another powerful
resource that will help in the fight for storing datasets with less
space, but still keeping good performance. Of course, this is just a
quick experiment with synthetic data, but I am pretty sure that the
new 'bitshuffle' filter will find a good niche in real world datasets.
Anyone interested in contributing some real data benchmark?
I'd like to thank Kiyo Masui for his help in this 'bitshuffle' backport.